Hadoop: HDFS en MapReduce
Aanleiding
Bij Info Support krijgen we steeds vaker de vraag of we lezingen of inhoudelijke kennis kunnen delen over ontwikkelingen in Big Data. De vragen variëren daarbij van het conceptueel meedenken (“hoe kunnen we anders met onze data omgaan? Welke data in ons bedrijf gebruiken we op dit moment niet en is potentieel interessant?”) tot aan het technisch meedenken in oplossingen (“Is een systeem met Hadoop een geschikte oplossing voor probleem x, of kan ik daar beter een relationeel database-systeem voor inzetten?”). Zonder al teveel in te gaan op de ontwikkelingen op het gebied Big Data, wil ik in deze post de achtergrond belichten van één van de technische oplossingen op het gebied van Big Data: Hadoop.
Hadoop: de basis
Met ‘Hadoop’ kunnen diverse zaken bedoeld worden. In de kern omvat Hadoop twee hoofdcomponenten: een integratie van opslag (HDFS) en een pattern om operaties op datasets gedistribueerd uit te voeren (MapReduce). In de praktijk wordt met ‘Hadoop’ echter ook een heel ecosysteem bedoeld wat samenwerkt of voortbouwt op deze kern. Hoewel er veel te vertellen is over de achtergrond en geschiedenis van Hadoop, ligt de focus in deze post op de werking van de kern: HDFS en MapReduce.
HDFS
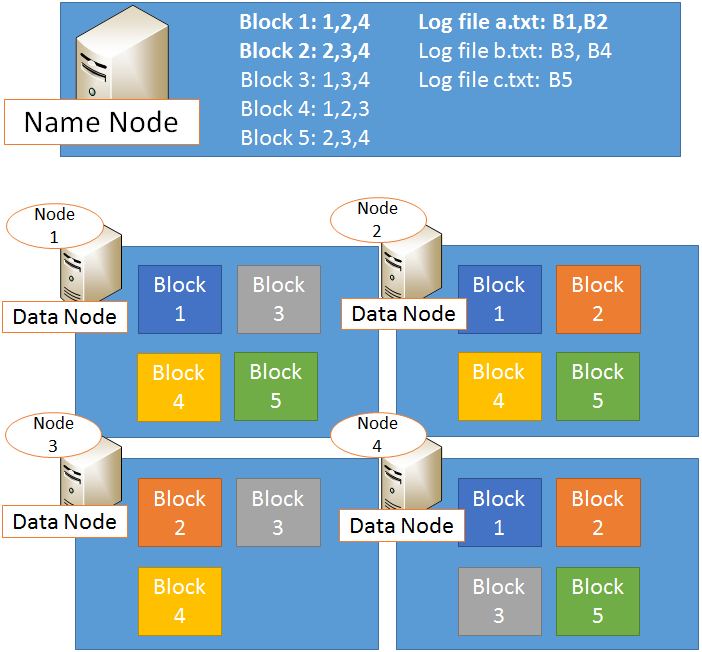
Binnen een Hadoop cluster wordt het Hadoop Distributed File System (HDFS) gebruikt als bestandssysteem. HDFS is een horizontaal schaalbaar bestandssysteem dat opgeslagen staat op een cluster van servers. De data wordt gedistribueerd opgeslagen, en het bestandssysteem zorgt automatisch voor replicatie van data over het cluster.
HDFS is toegespitst op het opslaan van grote datahoeveelheden, die vervolgens in batches verwerkt kunnen worden: denk hierbij aan bestanden van honderden megabytes, gigabytes of terabytes. Bij het opslaan op HDFS wordt elk bestand opgeknipt in diverse blokken van 64 MB. Deze blokken worden vervolgens gedistribueerd opgeslagen op de diverse nodes in het cluster, waarbij gezorgd wordt dat elk blok een bepaalde replicatiefactor bereikt: een minimum aantal keren dat een blok op het cluster is opgeslagen (standaard is de replicatiefactor 3). De nodes waar data wordt opgeslagen worden data nodes genoemd.

Wanneer er een node uitvalt, worden de blokken die op deze node stonden automatisch opnieuw verdeeld over het cluster, zodat de data dezelfde replicatiefactor behoudt.
De blokken waarin bestanden opgedeeld zijn, bevatten alleen data – er staat geen informatie in over waar zich andere blokken bevinden op het bestandssysteem, wat de oorspronkelijke bestandsnaam was waar de data in het blok deel van uitmaakte, of waar in het bestand dit blok zich bevond. Deze gegevens worden op aparte nodes opgeslagen. De node waar de relatie tussen bestandsnamen, blokken, en datanodes wordt bijgehouden heet de name node.

Deze aanpak van het inrichten van een opslag-cluster biedt enkele voordelen:
- Verwerken van grote bestanden gebeurt snel en efficiënt:
- Clients praten direct met de data nodes (weinig overhead in overdracht)
- Bestanden worden opgedeeld in blokken van 64 MB en verspreid over diverse data nodes opgeslagen (gedistribueerde overdracht)
- De architectuur van het systeem zorgt voor een horizontale schaalbaarheid: het systeem uitbreiden hoeft nooit door grotere (in verhouding duurdere) servers te kopen, maar kan altijd door meer van dezelfde servers erbij te pluggen, waarbij de opslag zowel als de rekencapaciteit lineair meeschaalt (over dit laatste zo meteen meer).
- Het systeem vraagt niet om speciale hardware. Zelfs RAID is niet nodig voor performance of betrouwbaarheid – alles wordt al in het ontwerp van het systeem opgevangen (er wordt vanuit gegaan dat hardware gegarandeerd zal falen).
Data Locality en MapReduce
Hoewel de bovengenoemde voordelen op zich al interessant zijn, komt de grote kracht van een Hadoop-systeem door het principe van data locality. Dit houdt in dat bij alle geplande data-vraagstukken rekening wordt gehouden met waar de data zich bevindt. Eén van de redenen daarvoor is, dat heen-en-weer-kopiëren van data relatief duur is: netwerkbandbreedte is beperkt, waardoor het de schaalbaarheid van het systeem in de weg kan staan. Daarom wordt er bij het opvragen van data vanuit HDFS altijd gekeken hoeveel hops de diverse name nodes van de aanvrager van de data verwijderd zijn, en eventuele clients krijgen bij het opvragen van data bij voorkeur nodes die zich qua netwerk-afstand dichtbij hen bevinden.
Het principe van data locality wordt nog verder doorgevoerd in het daadwerkelijk verwerken van data. Hierbij wordt zoveel mogelijk de berekening naar de data gebracht, in plaats van andersom. Hoewel niet niet alle berekeningen gedistribueerd uitgevoerd kunnen worden, blijkt zelfs dat bewerkingen die inherent een ‘samenvoegend’ punt nodig hebben (zoals sorteer-algoritmen) vaak opgesplitst kunnen worden in een decentraal deel (bijvoorbeeld een deel-aggregatie of een filtering van de input) en een centraal deel (het samenvoegen van data). Deze opsplitsing levert horizontale schaalbaarheid op, en kan verder gebruikmaken van het principe van data locality. Dit werkt met name voor grote batch-opdrachten erg goed.
Deze opsplitsing van verwerkingen in één of meer decentrale en centrale berekeningen wordt concreet gemaakt in het MapReduce patroon. Iets vereenvoudigd voorgesteld houdt dit in dat in de Map-fase op de data-nodes zelf een berekening uitgevoerd op de data. Vervolgens worden de resultaten hiervan verzameld, gesorteerd, en opnieuw verdeeld over een aantal nodes (de Shuffle-fase) voor een meer centrale verwerking – de Reduce-fase.
Hadoop vs. rdbms
Er zijn diverse verschillen in de manieren van opslag en verwerking tussen Hadoop en data-verwerkingssystemen als relationele databases. Op drie vlakken valt Hadoop in het bijzonder op:
- Horizontale schaalbaarheid is de basis, alle extra’s zijn mooi meegenomen
- Falen of uitvallen van systemen is normaal
- Berekeningen worden naar de data gebracht, in plaats van andersom
Dit maakt Hadoop bijzonder geschikt voor systemen waar veel data wordt opgeslagen, waar bijzonder grote bestanden worden geladen, en waar schaalbaarheid erg belangrijk is.
Tegelijk zijn er ook enkele gevallen waar Hadoop op dit moment duidelijk geen goede kandidaat is:
- Systemen met veel kleine bestanden – HDFS is geoptimaliseerd voor blokken van 64 MB of een veelvoud daarvan
- Systemen waar data ad-hoc benaderd moet worden – Hadoop is geoptimaliseerd voor het verwerken van batch opdrachten
- Systemen waarbij er ‘multiple writers’ zijn of bestanden gemodificeerd moeten worden
Conclusie
Bij het implementeren van een oplossing met Hadoop komt veel kijken. Naast een basisbegrip van de hierboven uitgelegde zaken is het belangrijk om een goed beeld te hebben van de aanwezige pakketten in het Hadoop-ecosysteem, en dit te kunnen plaatsen binnen de ontwikkelingen op het gebied van Big Data.
De ontwikkeling van Hadoop gaat door, het ecosysteem groeit en de diverse distributeurs bouwen hun eigen uitbreidingen en verbeteringen op Hadoop. Hoewel de distributeurs u graag vertellen welke features zij u aanbieden, is het lastig hier een objectief oordeel over te vellen.
Bij Info Support zijn we om deze reden een ééndaagse cursus ‘Essentials of Hadoop for Big Data’ gestart. Meer informatie over deze training is te vinden op http://training.infosupport.com/trainingen/essentials-of-hadoop-for-big-data.