Interpreteerbare AI als oplossing voor het Black Box Probleem: van paper naar demo (deel 1/2)

Het is een bekend probleem binnen Artificial Intelligence: het Black Box Probleem. Het model maakt een keuze, maar waar is deze keuze eigenlijk op gebaseerd? Deze keerzijde in conventionele AI zorgt voor weinig transparantie en zorgt er daardoor voor dat modellen moeilijk te controleren en daardoor lastig te vertrouwen zijn. Wat hierbij kan helpen is Interpretable AI; een model waarin de uitleg van keuzes by design in de output van het model zit verwerkt. Op die manier kan worden na gegaan waarom een model precies zijn keuzes maakt en kan het daardoor beter gecontroleerd worden.
In deze serie van twee blogposts leg ik aan de hand van een casus in Interpretable AI uit hoe je van het lezen van een paper toe kunt werken naar een werkende demo waarin de techniek wordt toegepast. Bovendien geef ik tips over waar je hierbij rekening mee moet houden. Ik geef stap voor stap aan hoe ik heb toegewerkt naar een demo applicatie die werkt met een model dat is getraind en gedeployd in een Azure cloud omgeving. In deze eerste blogpost heb ik het over het opzetten van een project, het opzetten van een omgeving en het trainen van een model. De volgende post zal gaan over het valideren van het model, het maken van de inference pipeline en het bouwen van de demo applicatie.
Plan van aanpak
Bij het opzetten van het project is het belangrijk om te bepalen wat het doel van het project is en hoe je daar kunt komen. Doel van dit project was om aan de hand van een reeds gepubliceerd paper, die methode na te bootsen in een demo om daar vervolgens een presentatie mee te kunnen maken. Om het probleem behapbaar te maken, is er voor gekozen om slechts met een subset van 10 klasses i.p.v. de 200 klasses van het originele paper te werken. Op die manier kan sneller een werkend voorbeeld gemaakt worden.
 Tip: maak het probleem klein om snel tot een resultaat te kunnen komen.
Tip: maak het probleem klein om snel tot een resultaat te kunnen komen.
Zodoende is dit project opgeknipt in de volgende stappen:
- Onderzoek naar techniek aan de hand van het paper
- Training van model dat gebruik maakt van de voorgestelde techniek (experiment)
- Testen en validatie van het model
- Maken van een demo applicatie
- Maken van een presentatie waarin de techniek hoogover wordt uitgelegd en wordt getoond in de demo
Literatuur
Als startpunt van het project is het paper This Looks Like That, Because… Explaining Prototypes for Interpretable Image Recognition gekozen. In dit paper wordt het idee naar voren gebracht om een artificieel neuraal netwerk te trainen waarvan de voorspellingen op een door mensen te begrijpen manier kan worden uitgelegd, namelijk volgens de volgende redenering: “dit is mijn voorspelling, omdat dit plaatje lijkt op dat plaatje dat ik tijdens de trainingsfase heb gezien”. Bij het lezen van het paper ontdekte ik al snel dat dit paper een uitbreiding is op het al bestaande paper This Looks Like That: Deep Learning for Interpretable Image Recognition. Het probleem is op die manier in te delen in 2 subproblemen:
- Train een model dat op basis van case-based reasoning met een prototype dat is geleerd tijdens de training kan uitleggen waar zijn voorspelling op gebaseerd is.
- Leg uit op welke manier het prototype lijkt op een test image, dat wil zeggen welke visual charateristics overeen komen.
Output van het geheel kan er dan uit zien zoals in de onderstaande afbeelding. In het kort wordt de keuze van het model om “White Pelican” als voorspelling te geven uitgelegd doordat de snavel en hals in de test image lijken op (looks like) een snavel en hals die het model tijdens training heeft gezien. Deze twee lijken op elkaar omdat de hue (kleurwaarde) en vormen overeen komen. Duidelijk is dat de keuze die het model heeft gemaakt op deze manier voor mensen interpreteerbaar is. Op deze manier kan daarom worden gecontroleerd of het model de juiste voorspelling maakt vanwege de juiste redenen.
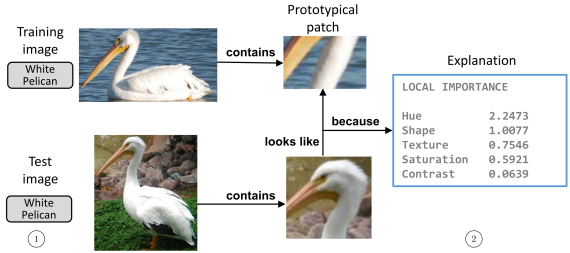
Tip: bij het starten van het project is het belangrijk de papers goed en eventueel meerdere keren te lezen om op die manier de methodes die worden voorgesteld goed te begrijpen.
Tip: lukt het bij het lezen van een paper de eerste keer niet om de techniek volledig te begrijpen, probeer het idee van de voogestelde methode dan toch hoogover te begrijpen en lees de meer technische stukken later nog een keer. Op die manier wordt ook de techniek later toch vaak duidelijk.
Tip: heb je na het lezen van een paper nog vragen en kom je er niet uit? Zoek contact met een van de schrijvers! Ze helpen je vaak graag verder.
Lokaal experiment
Het is belangrijk om tijdens het lezen van het paper na te gaan of er reeds een getraind model beschikbaar is dat is gepubliceerd door de auteurs. Is er niet een getraind model beschikbaar, ga dan na of er voldoende informatie in het paper staat om het naar code te kunnen vertalen zodat je op die manier het experiment na kunt bootsen. In mijn geval had ik het geluk dat de auteurs van de papers code hadden gepubliceerd waar ik mee aan de slag kon gaan. Verder is het handig om vroeg na te gaan of de dataset die gebruikt is in het paper vrij toegankelijk en te gebruiken is, dat was bij dit onderzoek het geval.
Tip: ga vroeg na of er een getraind model of code om een model te trainen is gepubliceerd, zodat je daarmee rekening kunt houden in je planning.
Tip: het beste is om te starten met een lokale implementatie zodat de overhead van het opzetten van een experiment in de cloud in eerste instantie niet nodig is.
Bij het doornemen van de code kwam ik er al snel achter dat deze met name bestond uit losse scripts. Deze scripts werkten welliswaar naar behoren in een experimentele setting, maar waren niet op een modulaire manier geschreven laat staan dat ze gebruikt konden worden in een training of inference pipeline of klaar waren voor gebruik in een cloud omgeving. Er was dus al snel duidelijk dat hier werk aan de winkel was om dit gebruiksklaar te maken voor mijn omgeving.
Wel was het mogelijk om redelijk snel een lokale trainingsrun aan te zetten, echter kwam ik er daarbij achter dat deze helaas niet werkte vanwege een tekort aan lokale computing resources. De volgende stap was dus noodgedwongen om nu al op te schalen naar training in de cloud.
Tip: probeer vroeg een lokaal experiment op te zetten, zodat je er achter komt of dit lokaal überhaupt mogelijk is of dat je al over moet stappen op training in de cloud.
Cloud experiment
Om een model te trainen en eventueel later te deployen in de cloud, heb ik een Azure Machine Learning workspace aangemaakt. Bij het opzetten van het experiment vind ik het fijn werken om van voren naar achter te werken, dus eerst de data klaarzetten in een blob storage, dan een datastore en dataset aanmaken zodat de data gebruikt kan worden in een experiment, dan een experiment opstellen die als output een model geeft en vervolgens kijken naar de inference pipeline.
Cookiecutter template
Door Info Supporter Willem Meints is een cookiecutter template ontwikkeld waarmee in enkele simpele stappen een Azure Machine Learning workspace kan worden opgezet. Het template bevat verder enkele scripts waarmee datasets kunnen worden aangemaakt en geregistreerd en geeft bovendien voorbeelden van scripts waarmee modellen kunnen worden getraind en gedeployd. Zowel de scripts in het template als de user interface in de Azure Machine Learning workspace kunnen worden gebruikt om deze taken mee uit te voeren. Hierbij heb ik er voor gekozen om zoveel mogelijk gebruik te maken van scripts, zodat deze makkelijk opnieuw gebruikt en geversioneerd kunnen worden.
Tip: het cookiecutter template dat door Willem Meints is ontwikkeld kan als een goed startpunt worden gebruikt bij het opzetten en uitvoeren van een experiment. Dit template is hier beschikbaar.
Tip: schrijf en gebruik zoveel mogelijk scripts zodat stappen die horen bij het opzetten en uitvoeren van experimenten makkelijk te herhalen zijn.
Data
Als eerste stap heb ik er voor gekozen om de dataset (CUB-200-2011) te uploaden naar een Azure Blob Storage. Omdat ik de dataset, zowel raw als pre-processed, al lokaal op mijn machine had staan als voorbereiding op het lokale experiment, was het kopiëren naar de blob storage een kwestie van het uitvoeren van enkele commands met AzCopy. Ik heb de originele dataset en de subset van 10 klasses als aparte datasets in de blob storage opgeslagen zodat ik eventueel later het experiment nog op zou kunnen schalen, indien nodig.
Tip: voor het kopiëren van data naar een Azure Blob Storage, kan AzCopy op een gemakkelijke manier worden gebruikt. Zie link.
Tip: voer data pre-processing offline uit zodat dit apart voor iedere training run hoeft te worden gedaan.
Nadat de data die benodigd is om een experiment te starten is geüpload naar een blob storage, moet er in de Azure Machine Learning workspace een datastore worden aangemaakt. Als je de workspace hebt aangemaakt via het Cookiecutter template, bevat de workspace reeds een default datastore. Anders kan dit simpelweg worden in de user interface of natuurlijk via de Python SDK.
Vervolgens is het belangrijk om gegeven de datastore, een dataset in de workspace aan te maken. De dataset is het object dat door experiments geladen zal worden en die als input voor een training run zal dienen. Een dataset kan worden aangemaakt via de user interface van de Azure Machine Learning workspace of de Python SDK. De datastore die in de vorige stap is aangemaakt dient te worden ingevuld en vervolgens kan worden aangegeven welke files uit de datastore aan de dataset moeten worden toegevoegd. In mijn geval wilde ik vanuit mijn datastore uit de folder train enkele niveaus diep alle .jpg files toevoegen aan mijn dataset, dus dat kwam neer op de volgende source: train/*/*/*.jpg.
Tip: voor het toevoegen van een dataset aan de workspace, kan de volgende guidance worden gebruikt, zie link.
Tip: voor het toevoegen van files van een datastore aan een dataset kunnen wildcards worden gebruikt. Voor voorbeelden zie link.
Infrastructuur
Compute nodes
Om training runs te kunnen draaien, dienen er compute nodes beschikbaar te zijn in de workspace om de experimenten op te kunnen draaien. Er kan eenvoudig een compute cluster worden aangemaakt middels het make_environment.py script in het Cookiecutter template. Hierbij heb ik er wel voor gekozen om het minimum aantal beschikbare nodes op 0 te zetten, zodat er niet dag en nacht een node bezet wordt gehouden om experimenten op te draaien. Verder was het bij dit project belangrijk dat de compute nodes een GPU bevatten, daarom is gekozen voor Standard NC6 nodes.
Environment
De code die bij een training run hoort, wordt uitgevoerd door een Docker container. Het is het van belang dat er een een Docker image wordt gecreëerd waar alle dependencies in zitten die nodig zijn om de trainingscode te draaien. Omdat ik van tevoren wist dat mijn code gebruik maakte van PyTorch, heb ik als startpunt een Dockerfile gebruikt dat bij een curated environment van Microsoft hoort. Extra dependencies die bij mijn code hoorden, heb ik daardoor toe kunnen voegen aan de Dockerfile. Vervolgens heb ik de Dockerfile geüpload in de workspace en is de gebuilde image daarin als environment opgeslagen. Op die manier kan deze omgeving eenvoudig hergebruikt worden door nieuwe training runs.
Tip: gebruik de Dockerfiles die horen bij de curated environments van Microsoft als startpunt om een environment in de workspace op te zetten. Een overzicht van de Dockerfiles is hier te vinden.
Tip: maak gebruik van environments waarmee je experimenten gedraaid kunnen worden. Deze kunnen in een Azure Machine Learning workspace eenvoudig geversioneerd en hergebruikt worden.
Training
Nu de dataset klaarstaat in de workspace en de juiste infrastructuur beschikbaar is, is het tijd om ons bezig te houden met de trainingsscripts. Het eerder genoemde Cookiecutter template bevat scripts waarmee experimenten gestart kunnen worden. Het belangrijkste in zo’n script is dat uit de workspace de juiste dataset geladen wordt, er een compute target en een environment gekozen worden, dat het juiste training script wordt aangeroepen en dat de uitkomsten van de training worden opgeslagen in de workspace. Meer guidance hierover en voorbeeldcode vind je hier.
Tip: bij het starten van een experiment is het belangrijk dat de source folder waar het training script in staat niet te groot is omdat dit zorgt voor onnodige start-up tijd doordat de volledige folder wordt geüpload naar de compute target. Zorg ervoor dat files die niet nodig zijn tijdens training wordt geexcluded door een .gitignore of .amlignore file toe te voegen. Meer informatie zie hier.
Het training script dat ik wilde gebruiken was niet door mijzelf, maar door de auteurs van het eerder genoemde paper geschreven. Het bestond uit een script dat geen parameters accepteerde en moest daarom worden omgeschreven waardoor het path naar de locatie van de data kon worden ontvangen en tevens zijn output (getraind model) naar de juiste output folder zou schrijven, in mijn geval /outputs.
Om de training te kunnen monitoren, wilde ik verder verschillende metrics terug kunnen zien in mijn experimenten in de Azure Machine Learning workspace. Het loggen van metrics kan worden gedaan door in het training script een Run object te instantiëren en middels de log methode metrics te loggen naar het experiment in de workspace. Op die manier kon ik in de gaten houden of mijn modellen überhaupt aan het leren waren en bijvoorbeeld niet aan het overfitten waren. Zo zie je in onderstaande figuur dat de accuracy op de trainingsset is opgelopen tot zo’n 100% en dat de accuracy op de testset is opgelopen tot zo’n 80%. Omdat de accuracy op de trainingsset een optimum lijkt te hebben bereikt en accuracy op de testset voldoende is, is dit vanwege het risico op overfitting een goed moment om te stoppen met de training.
Tip: Log metrics zoals training en validation loss en accuracy tijdens training om experimenten te monitoren.
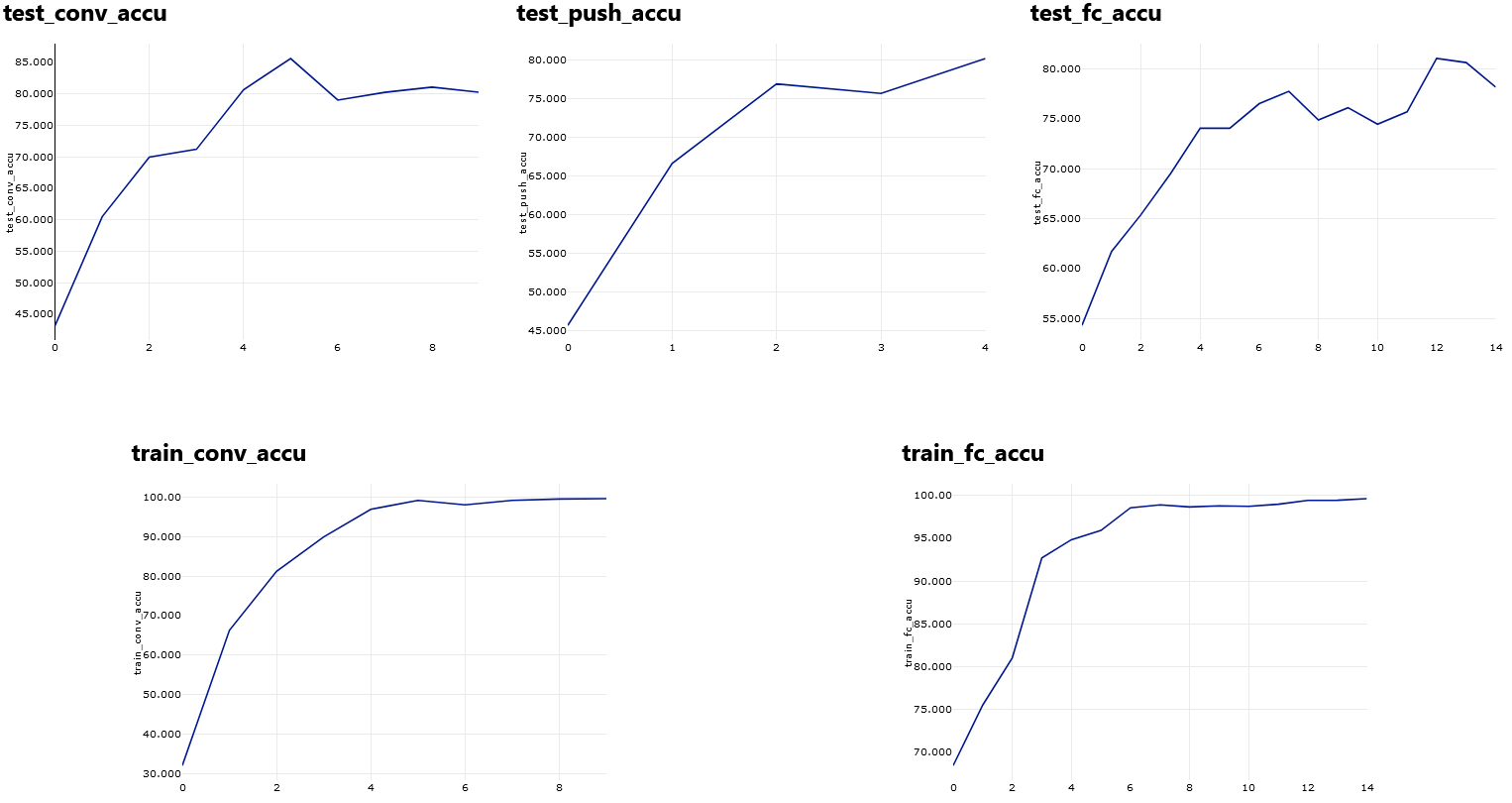
Metrieken die horen bij een trainingsrun
Aan het eind van de training is het zaak om het getrainde model te registreren in de workspace. Hierbij is het belangrijk om de metrics die zijn gelogd tijdens de training run mee te geven, zodat deze bij het geregistreerde model zichtbaar zijn. Eventuele extra informatie zoals het aantal epochs of de naam van de architectuur kan worden meegegeven als tag om modellen daarop te kunnen groeperen.
Tip: Geef informatie als validation accuracy mee aan een geregistreerd model, zodat je op die manier modellen met elkaar kunt vergelijken.
Tussenstand
Op dit moment is er een omgeving opgezet waarin een dataset staat en is er trainingscode beschikbaar waarmee modellen getraind kunnen worden. Bovendien is er al een trainingsrun geweest (zie figuur hierboven) waarbij het getrainde model redelijk goed voorspellingen lijkt te kunnen geven. In de volgende blogpost over dit onderwerp zal ik het hebben over het valideren van het model. Daarnaast dient er nog een inference pipeline te worden worden gebouwd, zodat de uitleg van de keuzes van het model gebruikt kan gaan worden in een demo applicatie.
Heb je in de tussentijd vragen? Laat hieronder gerust een reactie achter. In de volgende blogpost meer!