In het eerste artikel van deze reeks stond één vraag centraal: hoe houd je als organisatie grip op je data en afhankelijkheden in een veranderend cloudlandschap? Open source kwam daarbij naar voren als een serieus alternatief. Maar hoe ziet dat landschap er in de praktijk eigenlijk uit? In dit artikel belichten we een aantal core capabilities die elk dataplatform zou moeten hebben, en een aantal voorbeelden uit het open source datalandschap die invulling geven aan die capabilities.
Het open source datalandschap: volwassen, modulair en nog altijd in beweging

Er valt veel te kiezen
Wie vandaag naar het open source datalandschap kijkt, ziet al snel een wirwar van tools, frameworks en nieuwe standaarden. Onderstaande plaat, met daarin alle beschikbare open source data engineering tools, platformen en frameworks anno 2025, geeft dit goed weer.
Fig 1: Open Source Data Engineering Landscape 2025
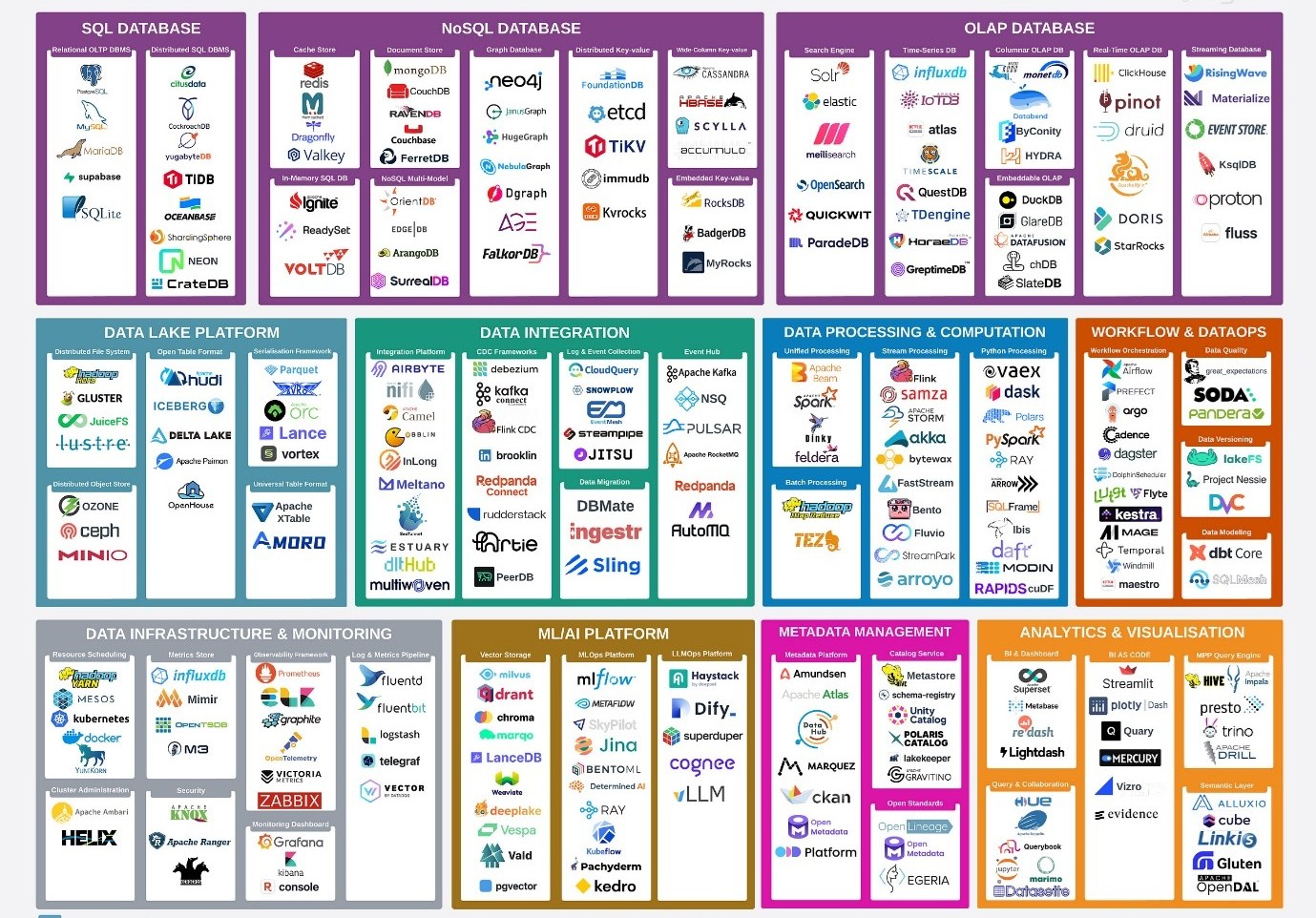
Er zijn inmiddels genoeg tools, packages en frameworks beschikbaar voor bijvoorbeeld ingestion, storage, governance en orchestration. Maar anders dan bij commerciële platformen vormen die geen kant-en-klaar geheel. Juist de kracht van open source zit in de combinatie van losse componenten. Dat biedt flexibiliteit, maar tegelijkertijd is er ook heel veel om uit te kiezen. En wat kies je dan?
Van één platform naar losse bouwblokken
Commerciële dataplatformen (denk aan Microsoft Fabric of Databricks) bieden vaak een geïntegreerde ervaring – binnen één platform-UI regel je het aansluiten van je bronnen tot en met het maken van rapportages over je data. Een open source dataplatform werkt fundamenteel anders. Geen alles-in-één oplossing, maar een verzameling ‘bouwblokken’ die samen een dataplatform vormen.
Dat klinkt complexer, en dat is het ook. Tegelijk biedt het iets wat in een tijd van toenemende afhankelijkheden steeds belangrijker wordt: keuzevrijheid. Organisaties kunnen per laag in de architectuur bepalen welke technologie het beste past bij hun eisen rondom performance, compliance, kosten of hosting.
Voor organisaties betekent dit wel dat samenhang tussen deze ‘bouwblokken’ niet vanzelf ontstaat. Die moet bewust ontworpen worden. De keuze voor een open source dataplatform komt daarmee ook met grotere verantwoordelijkheden: integratie, beheer en governance zijn vaak niet out-of-the-box ingericht.
Welke bouwblokken zijn nodig?
Of men nu de keuze maakt voor een SaaS-oplossing of voor open source: er is een aantal bouwblokken waar elk modern dataplatform minimaal in moet voorzien.
Fig 2: Bouwblokken Moderne Dataplatformen
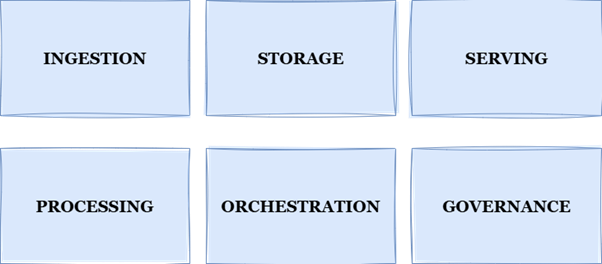
In dit artikel lichten we deze bouwblokken en de respectievelijke ontwikkelingen in het open source landschap per bouwblok toe.
Ingestion. Hier begint het allemaal: data verkrijgen vanuit de bron en opnemen in het platform. Ingestion kan, net als mogelijk is met bijvoorbeeld Microsoft Fabric, op zowel een low-code als high-code manier met behulp van open source tools. Tools zoals Airbyte maken het ontsluiten van databronnen toegankelijker, met een groeiend ecosysteem aan connectors.
Dataplatformen zijn vaak nog voornamelijk gericht op batchverwerking, maar real-time verwerking wordt steeds vaker een belangrijk onderdeel van de architectuur. Microsoft en Databricks geven hier ook gehoor aan in hun oplossingen. Streaming maakt use cases mogelijk zoals real-time monitoring en AI-toepassingen met actuele context. Interessante open source keuzes voor streaming/real-time capabilities in een dataplatform zijn Apache Kafka en Apache Flink.
Storage
Een van de grootste stappen in het open source landschap zit in de storage layer: de plek waar de data wordt opgeslagen in het platform.
Open table formats zoals Apache Iceberg, Delta Lake en Apache Hudi brengen database-achtige eigenschappen naar object storage. Denk aan transacties, versiebeheer en schema-evolutie.
Belangrijker nog: deze formaten maken het mogelijk om data los te koppelen van de engine die erop draait. Engines zoals Spark, Trino of Flink kunnen dezelfde data gebruiken zonder dat deze opnieuw verplaatst hoeft te worden. Dit voorkomt dat data technisch opgesloten raakt in één platform. Daarmee wordt het eenvoudiger om keuzes in compute, tooling of hosting later aan te passen, zonder ingrijpende migraties. Juist dat maakt deze ontwikkeling relevant in het kader van digitale autonomie en open source.
Orchestration
Ook wat betreft orchestration – het automatiseren, coördineren en beheren van de volledige workflow van data in het platform – is het open source landschap duidelijk volwassener geworden. Apache Airflow is uitgegroeid tot een brede standaard voor ETL-orchestration, met een groot ecosysteem aan integraties.
Er worden ook nieuwe concepten geïntroduceerd. Tools zoals Dagster zien pipelines niet langer als ‘losse taken’, maar als managed data-assets met expliciete afhankelijkheden. Dat is een volledig andere, maar zeer interessante, aanpak, grotendeels gebaseerd op Graph Theory.
Processing
Voor het bewerken van en waarde toevoegen aan data door middel van transformaties en processing zijn SQL en/of Python twee veelgekozen opties. Kies je voor SQL, dan is dbt een solide open source keuze, waarbij testen, documentatie en modellering standaard onderdeel worden van het ontwikkelproces.
Veel dataplatformen leunen nog sterk op het gebruik van Spark in combinatie met Python. Spark is een krachtig framework, maar het brengt ook aanzienlijke overhead met zich mee. Tegelijkertijd staat de ontwikkeling van rekenkracht niet stil: de hoeveelheid data die tegenwoordig op een enkele machine volledig in-memory verwerkt kan worden, is aanzienlijk gegroeid.
Daardoor is het in sommige gevallen niet langer nodig om Spark in te zetten. Met een open source dataplatform ontstaat meer flexibiliteit om hierin bewuste keuzes te maken. Je kunt dan bijvoorbeeld kiezen voor lichtere en efficiëntere libraries zoals Polars voor datatransformatie en -processing.
Governance
Een van de grootste veranderingen ten opzichte van enkele jaren geleden is de groeiende rol van governance, vaak de technische invulling van het bredere data governance-beleid binnen de organisatie. Dit was lange tijd een zwakker punt in het open source landschap.
Tools zoals OpenMetadata positioneren metadata, lineage en datakwaliteit als centrale laag, vergelijkbaar met bijvoorbeeld Databricks’ Unity Catalog. Niet als toevoeging achteraf, maar als onmisbaar onderdeel van het platform.
Serve
Dan het laatste onmisbare bouwblok: de serve-laag. Het is de plek waar verwerkte, opgeschoonde en gestructureerde data wordt aangeboden aan eindgebruikers. Ook hierin heeft het open source landschap veel te bieden. Trino heeft zich ontwikkeld tot een krachtige query-engine voor analytics over meerdere databronnen heen. DuckDB is ook een zeer geschikte optie. Voor visualisatie en dashboards biedt Apache Superset een volwassen open source alternatief voor veel BI-scenario’s. Maar ook Power BI is natuurlijk prima aan te sluiten op een verder open source dataplatform.
Dat betekent dat een open source dataplatform inmiddels de volledige keten kan ondersteunen: van opslag tot gebruik.
Tot slot
Het open source landschap voor dataplatformen is niet af, niet volledig gestandaardiseerd, maar wel volwassen genoeg om een serieus alternatief te vormen voor gevestigde platformen als Microsoft Fabric en Databricks. Inmiddels is duidelijk geworden dat een open source dataplatform vaak complexer in elkaar steekt dan andere platformen, maar toch weegt die complexiteit soms op tegen de voordelen die een organisatie ermee terugkrijgt: de flexibiliteit, onafhankelijkheid en allesomvattend: vergrote digitale autonomie.
In het volgende artikel maken we dit concreter in de vorm van een voorbeeldarchitectuur waarin alle eerdergenoemde bouwblokken samenkomen.