DWH voor informatica-studenten (deel 3: de praktijk)

In deel 1 en deel 2 van de serie “DWH voor informatica-studenten” is ingegaan op de vraag hoe we goede (en geldige) analyses kunnen doen op een transactioneel systeem. Er werd gesteld dat om geldige conclusies te trekken over oorzaken en gevolgen, er ook een geldig historisch plaatje van het transactionele systeem geschetst moest worden. Ook werd gesteld dat het belangrijk was dat relaties eenvoudig en duidelijk aanwezig zijn, en de structuur makkelijk te verkennen is. Maar voordat dat we data in dit soort structuren kunnen opslaan, is het handig de data vast lokaal op een systeem aanwezig te hebben! Daarom in deel 3 een praktijk-post, voordat we in deel 4 weer dieper op de stof insteken.
Scope en structuur van deze post
Zoals gezegd, zal deze post ingegaan worden op een stukje praktijk: het binnenhalen van de Twitter-data naar een lokaal systeem, en de vormgeving van dat systeem. Om de Twitter-data netjes binnen te halen zal allereerst gekeken worden naar het verbinding maken met Twitter. Aangezien de datastructuren van Twitter op dit moment nog onbekend zijn, zal vervolgens gekeken worden naar de structuren waarin de Twitter-data aangeboden wordt, en hoe die lokaal opgeslagen kunnen worden in een relationele database. Ten slotte zal de structuur van de applicatie in grote lijnen neergezet worden.
Code, or it didn’t happen…
Voor een meer in-depth beeld van de applicatie kan deze gevonden worden (met handleiding) op https://github.com/kooss/Twitter_DWH. Hier zijn ook de volgende zaken te vinden:
- Diagrammen die in deze blog gebruikt worden (in Visio zowel als PNG)
- SQL-code waarmee in MySQL de bijbehorende database gemaakt kan worden
- Python-code van de applicatie zelf
- README-instructies over het aanmaken en gebruiken van de applicatie
Mochten er zaken niet werken, schroom dan niet om me te benaderen! Mijn mailadres is af te leiden door mijn GitHub-gebruikersnaam te laten volgen door @ infosupport.com.
Achtergrond: ETL zonder tooling?
Wanneer je al wat meer bekend bent met Data Warehousing, kan de manier van aanpak in deze post wat vreemd overkomen: geen bekende modelleertechnieken, geen ETL-tooling of andere zaken die het leven veel makkelijker & gestructureerder maken. Zoals in de vorige post te lezen viel, wordt in deze weblogs bewust ingestoken op informatica-studenten – voorkennis van ETL-tooling, bijbehorende cursus en dergelijke zijn dus niet nodig, en we zullen in beginsel de tooling zelf programmeren. Maar allereerst is het zorg om de data überhaupt in de database te krijgen.
Verbinding met Twitter
Ok, tijd om aan de slag te gaan! Verbinding leggen met de Twitter API is vrij eenvoudig: de API is ontworpen conform de principes van Representational State Transfer (REST). Alle communicatie gebeurt door middel van HTTP-requests. De authenticatie met Twitter gaat via OAuth. Dit alles is goed gedocumenteerd in de Twitter developer documentatie op https://dev.twitter.com/docs. Voor veel programmeertalen zijn er bovendien wrappers en libraries beschikbaar voor de communicatie met Twitter.
De applicatie voor deze post is geschreven in Python, en maakt gebruikt van de tweepy library. Hiermee is de volgende code alles wat nodig is om verbinding te maken met de Twitter API:
import tweepy consumer_key = '' #Consumer key hier invullen consumer_secret = '' #Consumer secret hier invullen auth = tweepy.OAuthHandler(consumer_key, consumer_secret) api_connector = tweepy.API(auth)
Vervolgens is de API van Twitter eenvoudig te bedienen m.b.v. het zojuist verkregen API-object. Het uitlezen van de ‘home timeline’ gaat bijvoorbeeld als volgt:
laatste_status_id = 0 #id van de laatste status-message (tweet) die opgehaald is home_timeline = api_connector.home_timeline(since_id = laatste_status_id, count = 1)
Wanneer termen als ‘consumer key’ en ‘consumer secret’ onbekend voorkomen: dit maakt onderdeel uit van de Twitter-authenticatie.
Twitter-datastructuren
De Twitter API biedt data via XML, JSON, RSS en Atom aan. We kiezen hier om de data in JSON-formaat op te halen. Hoewel XML voordelen heeft als gedefinieerde datatypes, schema’s en andere zaken die de ETL een stuk makkelijker maken, leest XML wat minder prettig, en voegt XML veel meta-data toe aan de eigenlijke data. Voor nu houden we het zo simpel mogelijk en kiezen voor JSON.
Omdat we de data lokaal willen opslaan in een relationele database, is er een vertaalslag nodig van JSON naar de relationele database. Om die vertaalslag goed te kunnen maken, is het handig te weten hoe het datamodel eruit ziet wat door de JSON-structuur wordt beschreven. Op een zaterdagmiddag ben ik daar eens wat dieper ingedoken, en daar kwam de volgende schets uit (de kolomnamen zijn voor het overzicht even weggelaten):
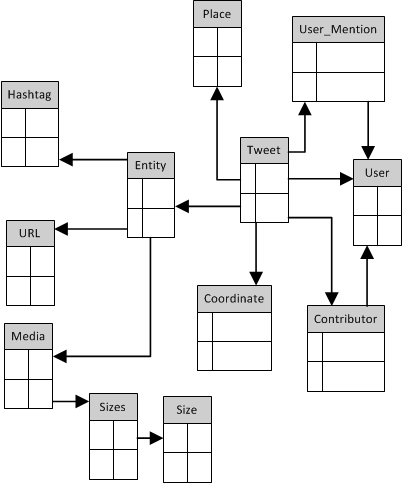
Hoewel het model complex genoeg is om interessante zaken mee uit te proberen, is het voor de doelstellingen in deze post iets te groot: hier is het hoofdzakelijk de bedoeling dat getoond wordt hoe de data vanaf Twitter naar het eigen systeem komt. Daarom wordt in de voorbeeld-applicatie het volgende, sterk vereenvoudigde model gebruikt:
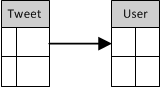
De lokale datastructuur
De lokale structuur is opgeslagen in een MySQL-database, waar ook de data vanuit Twitter opgeslagen gaat worden. Schematisch ziet het er als volgt uit (datatypes zijn hier weggelaten):

Eigenlijk is dit simpelweg een kopie van de data die Twitter via de API aanbiedt. Het grootste verschil eigenlijk is dat de datatypes nu vastgelegd zijn, evenals de foreign key. Wanneer dit werkt, is de applicatie vrij eenvoudig uit te breiden met meer tabellen.
De applicatie
Nu het datamodel gedefinieerd is (en in de database aanwezig) en de verbinding met Twitter gemaakt kan worden, is het slechts een kwestie van het daadwerkelijk ophalen van data & lokaal opslaan in de database. Deze code is eigenlijk vrij triviaal.
In de applicatie zijn daarnaast wat hulpmiddelen opgenomen voor de authenticatie met Twitter. Ook is wat logica opgenomen die ervoor zorgt dat alleen statussen worden opgehaald die nog niet eerder zijn meegenomen.
Conclusie
In deze post is een kleine, eenvoudige implementatie gepresenteerd van een applicatie die Twitter-data verzamelt en lokaal opslaat in een database. Teruggrijpend op deel 2, waar het principe van Extract, Transform en Load (ETL) uitgelegd werd, is nu het punt ‘Extract‘ geïmplementeerd: de data van de dynamische bron (Twitter) kan opgeslagen worden in een lokale database. Dit proces heet staging – het lokaal opslaan en ‘vastzetten’ van data, alvorens het verder te verwerken in het Data Warehouse.