Data, AI en Machine Learning zijn onderwerpen die veel kansen bieden in het zorgdomein. We genereren veel data en onderzoeken de mogelijkheden om deze data in te zetten voor het verbeteren van het leven een patiënt. Toch zijn er maar weinig voorbeelden van succesvolle AI of Big Data projecten die in de praktijk daadwerkelijk waarde hebben opgeleverd voor de zorg (Hansen, Miron-Shatz, Lau, & Paton, 2014; Sacristà & Dilla, 2015).
Data & AI in de zorg, van obstakels naar oplossingen

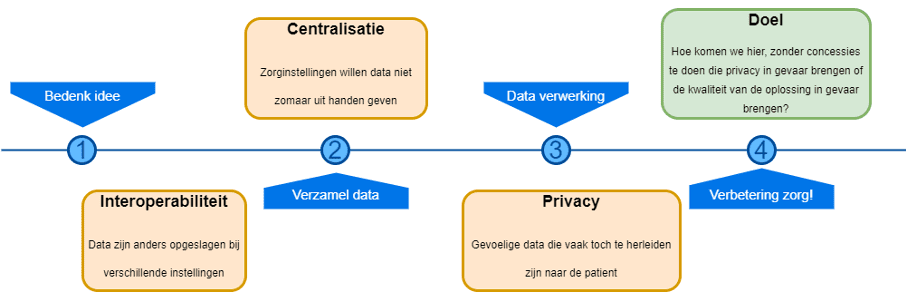
In een ideale wereld bedenk je een goed idee om met data de zorg beter te maken. Vervolgens verzamel je data, begin je met het begrijpen en schoonmaken van de data, voer je het algoritme uit en verkrijg je inzichten. Deze inzichten maken de zorg beter en helpen de patiënt vooruit! Helaas werkt het in de praktijk niet zo. Het blijkt namelijk lastig om de juiste data bij elkaar te krijgen om überhaupt te beginnen met het ontwikkelen van een oplossing. In dit artikel gaan we in op de belangrijkste obstakels om aan een goede dataverzameling te komen in het zorgdomein. Wij laten zien dat deze obstakels te overwinnen zijn met de nieuwste technieken op gebied van Data & AI. En we laten zien hoe we bij Info Support continu bezig zijn met het ontwikkelen van methodes om privacy te waarborgen.
De volgende obstakels kom je tegen bij het verzamelen van data in een AI-project waar de data zorg gerelateerd zijn:
- Interoperabiliteit van data van verschillende afdelingen en ziekenhuizen
Data worden opgeslagen in verschillende formaten of hebben niet dezelfde betekenis omdat gebruikt wordt gemaakt van andere codesystemen. Het vertalen van deze data naar een gemeenschappelijke definitie is tijdrovend en brengt risico’s met zich mee op het gebied van kwaliteit en betrouwbaarheid. - Centralisatie van data
Data zijn niet beschikbaar op 1 centrale plek maar gefragmenteerd over verschillende locaties. De zorginstellingen willen deze data niet zomaar verstrekken aan derden. - Privacy met betrekking tot gevoelige data
Privacy in de zorg is een groot issue, wat recentelijk alleen nog maar groter is geworden met de invoering van de AVG, waardoor het nog belangrijker is dat privacy echt gegarandeerd kan worden.
Interoperabiliteit van data
De interoperabiliteit van data is een probleem dat niet alleen voorkomt bij het toepassen van AI in de zorg. In onze podcast Software versterkt de mens leggen we dit probleem van data interoperabiliteit uit, door te laten zien dat data uitwisseling binnen de zorg nog regelmatig gebeurt met papiertjes die meegegeven worden aan de patiënt, om vervolgens personeel op een andere afdeling deze gegevens handmatig te laten invoeren. Dat is natuurlijk niet meer van deze tijd. Daarnaast worden de data op verschillende plaatsen verschillend opgeslagen, zodanig dat zelfs uitwisseling tussen verschillende afdelingen binnen een ziekenhuis tot grote problemen kan leiden. Door deze factoren is het lastig om data samen te brengen en te analyseren. Toch zien wij dat dit probleem opgelost kan worden.
Vanuit de overheid is het Medmij-programma opgezet. Hiermee krijgt de patiënt meer grip op zijn/haar data in de zorg, door de beschikbaarheid van alle data via een zogenaamde persoonlijke gezondheidsomgeving (PGO). Hiervoor wordt FHIR (Fast Healthcare Interoperability Resources) gebruikt. FHIR is een standaard om digitaal gegevens uit te wisselen binnen en tussen zorginstellingen. Het belangrijkste van FHIR is dat er een wereld ontstaat waar datauitwisseling in de zorg mogelijk is, waardoor data uit verschillende bronnen binnen de zorg bij elkaar gebracht kunnen worden tot 1 dataset. In theorie kan iedereen die is aangesloten op Medmij deze data gebruiken en het aantal zorgaanbieders gaat de komende periode explosief groeien.
Met FHIR krijg je interoperabiliteit van data tussen zorgaanbieders. Doordat zij in dezelfde standaard met elkaar communiceren, worden datasets gecreëerd die geschikt zijn voor analyse met AI. Naar verwachting zullen deze datasets meer dan voldoende data bevatten door de grote groei van het gebruik van FHIR. Met FHIR is interoperabiliteit van data geen probleem meer en is het eerste obstakel van AI in de zorg overwonnen.
FHIR
De zorgsector zit midden in een grote digitale transformatie. Ook de standaarden voor informatie-uitwisseling binnen zorgapplicaties ontwikkelen in snel tempo mee. Met FHIR (Fast Healthcare Interoperability Resources) is er een nieuwe HL7-standaard, waarmee snel en gemakkelijk digitale gegevens kunnen worden uitgewisseld binnen de zorg.
Centralisatie van data
Nu we met behulp van FHIR een gemeenschappelijk definitie hebben van de data, is het in theorie nu eenvoudig om alle data bij elkaar te brengen en vervolgens AI toe te passen. Toch is dat helaas in de zorg niet zo eenvoudig als het lijkt. De verschillende partijen in de zorg willen niet zomaar hun data afstaan, waardoor je uiteindelijk nog steeds niet een grote dataset bij elkaar krijgt. Het is wenselijk om zo veel mogelijk data bij elkaar te krijgen voor betere analyses. Met behulp van FHIR is dat nu mogelijk. Echter, is het te kort door de bocht om te verwachten dat ziekenhuizen zomaar hun data uit handen geven vanwege alle regelgeving die gebonden is aan deze gevoelige data.
We kunnen nu beargumenteren hoe jammer dat is, hoe veel voordelen we kunnen halen uit het doen van de analyses met AI, en hoe belangrijk het is om daarvoor zo veel mogelijk data bij elkaar te krijgen, om zo alle partijen te overtuigen om de data te af te staan. Maar we kunnen dat ook niet doen, en de data simpelweg op locatie laten staan.
Federated Learning
De regelgeving is er immers niet voor niets, en juist in de zorg is het goed om de privacy van kwetsbare patiënten goed te beschermen. In plaats daarvan een centrale analyse, brengen we de analyse naar de data. Dit heet Federated Learning (Yang et al., n.d.). Federated Learning is in 2016 bedacht om machine learning lokaal toe te kunnen passen, zonder dat data van een device worden verplaatst. Hierbij wordt een algoritme lokaal getraind en worden de resultaten samengevoegd met een overkoepelende versie van het algoritme. Niet de data verlaten de omgeving maar wel een getraind model op basis van de data. Door Federated Learning toe te passen verlaten de data het ziekenhuis niet, maar de waardevolle inzichten daaruit wel!
Privacy
Een groot deel van het privacy probleem kun je oplossen door Federated Learning. Toch is alleen het toepassen van Federated Learning niet waterdicht op het gebied van privacy. Je kunt gevallen bedenken waarbij de data kleinschalig zijn, en je via de aanpassingen in het algoritme deze kan herleiden naar een individu. Ondanks dat de data de oorspronkelijke locatie niet verlaten, verlaat een herleidbare versie de oorspronkelijke locatie wel. Dat is evengoed in strijd met de normen rondom privacy. Ook met deze randgevallen moet je rekening houden. Vooral omdat deze randgevallen in de zorg voorkomen, want elke patiënt is uniek en sommige ziektes zijn simpelweg zeldzaam. Ook voor deze gevallen willen we AI toepassen, maar wel op een manier die de privacy van de patiënt waarborgt. Bij Info Support doen we daar veel onderzoek naar. Twee van deze onderzoeken bieden mogelijkheden om privacy beter te kunnen garanderen.
Als je de leeftijd vervangt door een categorie van leeftijden, dan is het opeens een stuk lastiger om iemand te herleiden ..
In het eerste onderzoek laten we zien dat het mogelijk is om te voorkomen dat een dataelement gemakkelijk te herleiden is naar een bepaald persoon, door ervoor te zorgen dat er een minimaal aantal vergelijkbare datapunten in de dataset aanwezig is. Stel dat een dataset een groep mensen bevat waarvan we alleen de leeftijd en een medische historie kunnen zien. De data lijken anoniem, maar dat hoeven deze niet te zijn.
Privacy verbeteren
Als ik weet dat een vriend van mij in deze dataset zit en dat hij de enige is die 35 jaar is, dan kan ik hem identificeren en opmaken welke medische historie bij hem hoort. Als je echter de leeftijd vervangt door een categorie van leeftijden, bijvoorbeeld 30 tot 35 jarigen, dan valt deze vriend van 35 samen met iemand van bijvoorbeeld 30 of 33 jaar. Dan is het opeens een stuk lastiger om te herleiden welke medische historie hoort bij de persoon met een leeftijd van 35. Nu zijn er meerdere mogelijkheden. Dit heet k-means anonimity, waarbij een algoritme de privacygraad tot op zekere hoogte kan garanderen aan de hand van hoeveel (k) vergelijkbare gevallen die er aanwezig moeten zijn in de dataset. Een algoritme kan de dataset zodanig slim aanpassen door de datavelden te groeperen met zo weinig mogelijk impact op een eventuele analyse, maar dat er altijd k vergelijkbare gevallen in de dataset aanwezig zullen zijn. Het volledige onderzoek te vinden op de Info Support research pagina.
Het risico van het gebruik van deze methode is echter wel dat de datakwaliteit minder wordt. Ook is het in geval van zeldzame ziektes niet altijd mogelijk om de k-means anonimity methode toe te passen.
Differential Privacy
Daarom is Info Support verder gaan kijken naar Differential Privacy (Dwork, 2008). Differential Privacy algoritmen kan je gebruiken om data betrouwbaar te anonimiseren op basis van wiskundige methoden. In een vervolgonderzoek op het bovengenoemde onderzoek is Craig Leek, masterstudent AI en afstudeerder bij Info Support, bezig met het bouwen van een framework dat in staat zal zijn om tegelijkertijd privacy te garanderen en de datakwaliteit zo hoog mogelijk te houden. Tijdens het schrijven van dit artikel is het framework nog niet af, maar de resultaten zullen binnenkort verschijnen op research.www.infosupport.com.
Wat wel duidelijk geworden is, is dat we privacy problemen kunnen oplossen met behulp van de nieuwste technieken. Door k-means anonymity en differential privacy zijn we in staat om privacy op een wiskundige manier te garanderen, en zo ook het laatste obstakel voor het toepassen van AI in de zorg, uit de weg te helpen.
Conclusie
Door met een open mindset op het probleem af te gaan, is er altijd een oplossing te vinden waarbij we niet of nauwelijks compromissen hoeven te sluiten. De kracht van AI kan ook in een lastig speelveld als de zorg, volledig tot zijn recht komen. We hebben in dit artikel laten zien hoe het mogelijk is om met behulp van FHIR overal in de zorg, data te kunnen begrijpen. Federated Learning is inzetbaar om resultaten samen te laten te komen, zonder dat data worden verplaatst om zo privacy te beschermen. Vervolgens zijn we in staat om met behulp van verschillende Differential Privacy technieken de privacy te garanderen met wiskundige methoden.
Vervolgstappen
De volgende stap is het analyseren van deze data. Ook hier vinden we er in de zorg grote uitdagingen die zeer specifiek zijn voor het domein. In de Whitepaper ‘Small Data en Active Learning in de zorg’ leggen wij uit wat deze problemen zijn en hoe wij deze op kunnen lossen
Kennis uit de markt voor u!
Artificial Intelligence (AI) is een uitermate krachtige technologie die de zorg gaat ontzorgen: routinematige taken worden uit handen genomen, immense datasets worden in een handomdraai gescand en zorgprofessionals krijgen meer tijd voor hun patiënten. Maar voor het zo ver is, moet je wel ergens beginnen. Hoe je dit als zorgprofessional op de juist…
Download