Ongestructureerde data hebben de toekomst
8 april 2022 – door Tea Stojanovic (IT-consultant bij Info Support) en Niels Naglé (Data Architect bij Info Support)
Dit artikel is eerder gepubliceerd in AG Connect (print en online).
Ongestructureerde data zijn nog in grote hoeveelheden aanwezig. Weggooien is zonde. Maar omzetten van ongestructureerde naar gestructureerde data is een fikse taak. Met kunstmatige intelligentie (AI) op basis van machine learning kan een groot deel van dit werk echter geautomatiseerd worden en worden die data bruikbaar, constateren Tea Stojanovic en Niels Naglé. Want ook ongestructureerde data hebben wel degelijk structuur.
De laatste jaren wordt er steeds meer gesproken over datagedreven bedrijven. Mede door de coronapandemie zijn ook minder of zelfs niet-technische bedrijven afhankelijker geworden van digitale oplossingen. Er wordt steeds meer data verzameld en gedeeld met andere partijen, die allemaal verschillende manieren hanteren om deze gegevens op te slaan, te gebruiken, te presenteren en verder te delen.
De huidige aandacht voor alles rondom data is met name gericht op gestructureerde data, terwijl op dit moment 80 tot 90 procent van de data binnen bedrijven ongestructureerd is. Hierdoor blijft er nog heel veel informatie ongebruikt, wat enorm zonde is. Bovendien is dit risicovol en onnodig, want met ongestructureerde data kun je veel meer dan je in eerste instantie denkt. Nu is de tijd om ook hier de waarde uit te gaan halen.
Gestructureerde data worden al jaren actief gebruikt binnen verschillende systemen en processen. Hoe meer relevante inzichten een bedrijf heeft, hoe beter het de juiste beslissingen kan nemen. Data worden daardoor steeds vaker gezien als het nieuwe goud, als de bron voor fact-based decision-making. Denk bijvoorbeeld aan een relationele database, waarbij de verschillende gegevens met elkaar in verbinding staan. Hierdoor zijn het model en de onderlinge afhankelijkheden meteen duidelijk en kan de ontvanger de data goed lezen en gebruiken.
Data wordt daardoor steeds vaker gezien als het nieuwe goud, als de bron voor fact-based decision-making. Een goed voorbeeld van gestructureerde data is een relationele database, waarbij de verschillende gegevens met elkaar in verbinding staan. Hierdoor zijn het model en de onderlinge afhankelijkheden meteen duidelijk en kan de ontvanger de data goed lezen en gebruiken.
Aan de andere kant staat de ongestructureerde data, zoals PDF- en andere tekstbestanden, afbeeldingen of video’s. Anders dan de naam doet vermoeden, hebben deze gegevens vaak overigens wél een bepaalde structuur en is het dus geen ‘berg’ willekeurige gegevens.
Voordelen en risico's
Ongestructureerde data bevat gegevens die worden verzameld en opgeslagen bij dagelijkse zakelijke activiteiten, zoals de verwerking van logs, e-mails, formulieren en andere tekstdocumenten. Vaak is er geen compleet overzicht van deze data en is het zelfs nog niet bekend waar deze gegevens precies voor gebruikt kunnen worden, omdat ze niet aansluiten bij de huidige systemen. Toch durven bedrijven deze data ook weer niet te verwijderen, omdat deze gegevens mogelijk waardevolle inzichten bevatten.
Het voordeel van ongestructureerde data is wel dat deze eenvoudig en goedkoop op te slaan is, aangezien er geen vaste structuur voor opslag nodig is. Dit geeft meer flexibiliteit bij wijzigingen in systemen en/of gegevensuitwisseling tussen systemen en organisaties. Overigens kan het wel gevaarlijk zijn als je deze data alleen maar opslaat en niet analyseert. Zo kan er privacygevoelige informatie in staan terwijl je daar helemaal geen weet van hebt.
Dit kan op basis van de Algemene verordening gegevensbescherming (AVG) voor de nodige problemen zorgen. Daarom is meer dan de moeite waard (en soms zelfs noodzakelijk) om data op de juiste wijze te beheren. Vaak (en met name bij grote hoeveelheden gegevens) blijft het echter een uitdaging om deze ongestructureerde data uit te wisselen en op te slaan in de huidige systemen, laat staan om ze te analyseren. Zo voeren medewerkers meestal zelf ongestructureerde gegevens uit bijvoorbeeld PDF-documenten handmatig in interne databases in, omdat er nog geen efficiënt geautomatiseerd alternatief is.
Het vergt dus veel werk om data zo te verwerken dat deze in de huidige systemen past (aangezien deze – wederom – gestructureerd zijn). Deze kennis is vaak niet of in beperkte mate voor handen, omdat de skillset van medewerkers en de te gebruiken tools nog te veel zijn afgestemd op gestructureerde relationele databases.
Using unstructured data with AI
Datamanagement, AI en ML
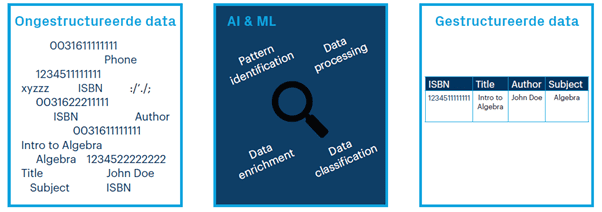
Door de significante ontwikkelingen op het gebied van datamanagement, kunstmatige intelligentie (AI) en machine learning (ML), is het inmiddels steeds vaker mogelijk om de gewenste structuur aan te brengen in verkregen ongestructureerde data. AI brengt immers de grootste bedrijfswaarde in het vinden van patronen en structuren op grote datasets en dat maakt AI het meest geschikt om structuur te vinden in ongestructureerde data. Dit betekent dat de data in het originele formaat wordt uitgewisseld en dat de ontvangende partij kiest of hij er direct structuur aan geeft.
Als alternatief kunnen gegevens worden opgeslagen als ongestructureerd en worden getransformeerd wanneer we ze willen analyseren of gebruiken voor een bepaald doel. Om de controle te behouden en tegelijkertijd tijd te besparen, zijn de meeste taken geautomatiseerd, maar de uiteindelijke validatie gebeurt altijd door mensen als de situatie daar om vraagt en/of de zekerheid onder een bepaalde drempel zakt.
Op die manier kun je als organisatie dus profiteren van het beste van twee werelden: alle voordelen van de volledige, snelle en flexibele ongestructureerde data en de eenvoud en het gemak van gestructureerde data. Een heel mooi vooruitzicht dus, dat is gebaseerd op de mogelijkheden van ongestructureerde data.
De oplossing in de praktijk
We nemen als voorbeeld een online boekhandel die spreadsheets ontvangt met voor elk boek de naam, de verkoopprijs, bepaalde metadata (ISBN-nummer, genre, auteur, bindmethode, aantal pagina’s, afmetingen), het totaal aantal boeken per categorie en eventueel afbeeldingen van omslagen en korte samenvattingen. Al deze informatie moet opnieuw worden ingevoerd in andere systemen waarin de voorraadniveaus en andere productgegevens worden bijgehouden. Om de informatie op de website te kunnen weergeven, moet de boekhandel de informatie uploaden en aanvullen met de juiste gegevens uit de spreadsheet.
In het ideale geval kunnen bepaalde delen van de informatie (bijvoorbeeld de afbeelding van het omslag) worden getagd, zodat ze later opnieuw gebruikt kunnen worden. De boekhandel ontvangt boeken van een groot aantal leveranciers, die de meeste productinformatie en metadata aanleveren in Excel-bestanden, eventueel aangevuld met samenvattingen (als PDF) en omslagfoto’s in JPG-bestanden. Sommige leveranciers zetten alles (inclusief de foto’s) in het Excel-bestand, terwijl andere de gegevens liever in afzonderlijke bestanden aanleveren.
Op dit moment moeten medewerkers van de boekhandel de binnenkomende bestanden dus nog handmatig doornemen en de informatie via een speciale interface invoeren in de interne systemen. Er zijn echter grote overeenkomsten tussen de informatie in de verschillende bestanden, ongeacht de precieze bestandsformaten. Alle bestanden bevatten immers informatie over bijvoorbeeld de titel, ISBN, prijs en auteur.
Vanwege de beperkingen van de traditionele software moeten de medewerkers alle bestanden openen om de informatie te extraheren. Op basis van hun kennis en ervaring weten de medewerkers wel welke informatie ze waar kunnen vinden.
Het is steeds vaker mogelijk om structuur aan te brengen in ongestructureerde data
Tea Stojanovic, AI- & IT-onderzoeker en consultant bij Info Support.
Toegevoegde waarde van AI
Deze omvangrijke taak kan echter worden uitgevoerd met AI. AI-tools op basis van machine learning zijn namelijk heel goed in staat om patronen in data te herkennen en de onderliggende logica (zoals clusters en relaties) in kaart te brengen. Alle benodigde stappen kunnen prima worden geautomatiseerd met deze tools.
Net zoals dat medewerkers de inhoud snel kunnen identificeren aan de hand van de patronen die ze uit ervaring kennen, kan ook een machine learning-model dit leren via speciale datasets voor trainingsdoeleinden. Deze geautomatiseerde methode is veel sneller dan een proces waarin de gegevens handmatig moeten worden ingevoerd in een interface voor de interne systemen.
Aangezien het belangrijk is dat mensen de volledige controle houden over de informatie die in het systeem wordt ingevoerd, werken de makers van de machine learning-modellen nauw samen met klanten om een verzameling passende evaluatoren te ontwikkelen. De volgende evaluatoren worden hier vaak voor gebruikt:
- Betrouwbaarheid: deze evaluator geeft informatie over het aandeel correcte voorspellingen
- Precisie: deze evaluator geeft informatie over de relevantie van geselecteerde items
- Recall: deze evaluator geeft informatie over het aantal relevante items onder de geselecteerde items.
Al deze parameters helpen ons op verschillende manieren te beoordelen of we de juiste data afleiden uit de bestanden. Dankzij deze automatisering houden de medewerkers meer tijd over voor andere taken, terwijl ze toch maximale controle houden over wat er in het systeem wordt ingevoerd. Bovendien kan de ontvangende partij zich concentreren op de inhoud zonder zich te hoeven bekommeren om de juiste gegevensindeling. Correcte herkenning van de bestandsindeling is een van de patronen waarin het machine learning-model kan worden getraind.
Van ongestructureerd naar gestructureerd
Om de transformatie van ongestructureerde data naar de gewenste structuur te automatiseren, moeten een aantal vaste stappen worden uitgevoerd.
We gebruiken hiervoor het voorbeeld van de boekhandel, maar deze stappen zijn op alle soorten ongestructureerde data die gestructureerd moeten worden van toepassing:
- Herkennen van structuren in de data. Bijvoorbeeld: alle velden in de kolom met de titel ISBN zijn numerieke waarden. Bij publicaties van vóór 2006 bestaan deze nummers uit tien cijfers, daarna uit dertien cijfers.
- Categoriseren van de data. Deze stap is te vergelijken met het instellen van een filter waarbij verschillende categorieën worden onderscheiden. Bijvoorbeeld: genres zijn bepaalde waarden die vaak terugkeren, zoals fictie, non-fictie, en biografie. ISBN-nummers zijn altijd numeriek, evenals telefoonnummers. Het eerste deel van telefoonnummers is vaak hetzelfde, zoals 00316 bij Nederlandse mobiele nummers.
- Herkennen van relaties. Via correlatie kunnen we bepalen in hoeverre er een lineaire relatie is tussen twee variabelen. De sterkte van de correlatie kan worden uitgedrukt in een getal tussen -1 (negatieve correlatie: hoe hoger de ene variabele, des te lager de andere variabele) en +1 (positieve correlatie: hoe hoger de ene variabele, des te hoger ook de andere variabele).
- Transformeren naar de gewenste structuur. In deze stap wordt bijvoorbeeld beslist of een bepaald nummer een ISBN-nummer of een Nederlands telefoonnummer is. Zo kan een nummer dat met 00316 begint, met een betrouwbaarheid van 75 procent worden aangemerkt als een Nederlands telefoonnummer. Als de betrouwbaarheid onder de vastgestelde drempelwaarde blijft, moet de beslissing wel worden geverifieerd door een medewerker.
- Opslag in een geschikte indeling. Na afloop van de transformatie is de data passend gemaakt voor een relationele database. De data kan nu ofwel in de relationele database worden opgeslagen, of in de ruwe, ongestructureerde vorm bewaard blijven totdat je klaar bent om de data te analyseren en te verwerken.
Nu is de tijd om de risico’s van de ongestructureerde data te minimaliseren en de kansen te vergroten om ook deze data om te zetten naar waarde voor de organisatie.
Om hier de eerste stappen in te kunnen zetten, gebruiken we vanuit Info Support de AI Design Week: een in de praktijk bewezen aanpak waarmee je in korte tijd inzicht krijgt in de risico’s en kansen van je eigen ongestructureerde data.
Gids: AI Design Week
In deze gids vertellen we u hoe u binnen vijf dagen de waarde van uw AI-ideeën kunt bewijzen.
We laten u zien hoe u het beste AI-idee selecteert dat past bij uw bedrijfsdoelen om een waardevolle impact te garanderen.
Met andere woorden, we combineren technische zorgvuldigheid met zakelijke zorgvuldigheid.
Info Support Redactie
Redacteur