Writing your own Robocopy-over-HTTP Cmdlet
In this blog post, I’ll show how to write a Cmdlet in C# that is capable of exploring and downloading an entire virtual directory hierarchy from an IIS-based webserver, much like robocopy or xcopy can do for regular folders. Combined with my previous post that explains how IIS can be leveraged as a generic file hosting service, this effectively provides an HTTP(s)-based (and hence, more firewall-friendly) alternative to file shares or FTP.
By making this functionality available as a cmdlet, the opportunity for reuse is maximized – we can now use it in any Powershell script that requires file transfer through a firewall, e.g. as part of an automated deployment script.
The other reason that I chose to implement this as a cmdlet is that it provides an ideal opportunity to blog about the various bits and pieces that go into writing your own cmdlet in C#. As you will see, this is actually very easy, but it helps to have a reference implementation – and this post is intended as such a reference implementation. At least for me, but hopefully for you too.
So lets get started.
Prerequisites
I assume you already have an IIS virtual directory configured that stores the files to be downloaded. To ensure that none of these files will be interpreted or blocked by IIS, I recommend you configure this virtual directory so that it serves all file types, as explained here.
This virtual directory also needs to have directory browsing enabled, so that IIS will list the contents of each directory as a simple web page. Our cmdlet will parse and interpret these directory listings, so that it is able to recursively explore the entire virtual directory.
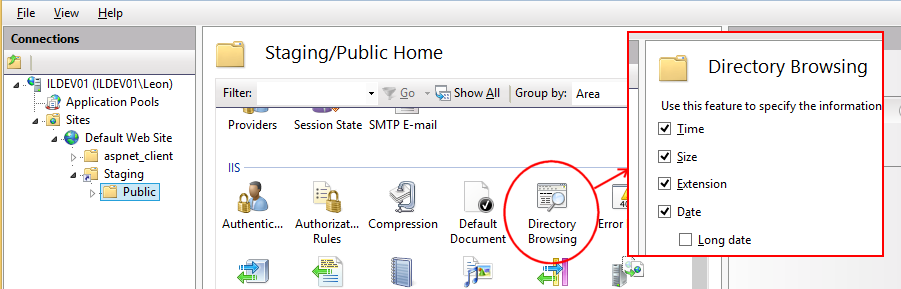
Enabling IIS virtual directory browsing
Once enabled, requesting a directory listing will result in a simple webpage with all files and folders:
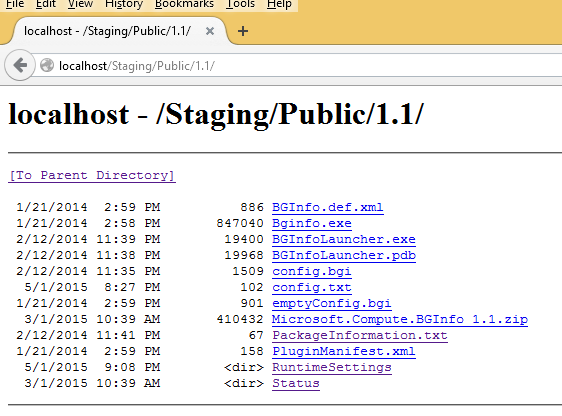
Cmdlet outline
Creating a Cmdlet starts by creating a new Class Library project from Visual Studio and referencing the System.Management.Automation assembly, which should be located in C:Program Files (x86)Reference AssembliesMicrosoftWindowsPowerShell3.0 if you have the Windows SDK installed. Otherwise, you can also get it through NuGet.
In order to make our class a cmdlet, we’ll have it derive from Cmdlet and attribute it with the verb and noun parts that make up the name of our cmdlet – in this case, our cmdlet will be called Copy-FromHttp.
We also could have used PSCmdlet as the base class for our cmdlet, which provides more integration with the Powershell runtime to allow access to session variables and execution of powershell scripts.
However, unlike a Cmdlet-derived type, it also means that you cannot use the cmdlet’s functionality from outside Powershell, which can be a limitation. Because we don’t need any of the extra functionality, we’re going to stick with the more lightweight Cmdlet base class.
As you can see each parameter is represented as a public property. Note that “flags” parameters (i.e. parameters whose value is determined by being either present or absent on the command line) are of type SwitchParameter.
Also note that, if the Path parameter is not specified, we want the files to be written to the current location (i.e. $pwd), and the SessionState can provide us with that. This is different from Environment.CurrentDirectory which you use in a regular console application, because in powershell it will refer to the location from which your Cmdlet assembly was loaded.
[Cmdlet(VerbsCommon.Copy, "FromHttp")]
public class CopyFromHttpCmdlet : Cmdlet
{
[Parameter(Position = 0, Mandatory = true,
HelpMessage = "The HTTP directory url to download files and directories from. Required.")]
public string SourceUrl { get; set; }
[Parameter(Position = 1,
HelpMessage = "Where to store the downloaded files and directores. Optional, defaults to the current folder.")]
public string Path { get; set; }
/// <summary></summary>
[Parameter(HelpMessage = "If specified, copies all files recursively. Otherwise only copies the files in the current directory.")]
public SwitchParameter Recurse { get; set; }
private int _fileCount;
private int _directoryCount;
private WebClient _client;
protected override void BeginProcessing()
{
_fileCount = 0;
_directoryCount = 0;
_client = new WebClient();
//Since we only copy entire directories, the SourceUrl must refer to a directory,
//and therefore end in a slash.
string sourceUrl = this.SourceUrl;
if (sourceUrl.EndsWith("/") == false)
sourceUrl += "/";
//If no targetPath is specified, default to the current *location*. Note that we need
//to obtain it through the current SessionState; Environment.CurrentDirectory returns
//the current *directory*, which is something else.
string targetPath = this.Path;
if (string.IsNullOrEmpty(targetPath))
{
SessionState ss = new SessionState();
targetPath = ss.Path.CurrentFileSystemLocation.Path;
}
Download(new Uri(sourceUrl), targetPath);
}
//...
}
Recursive directory exploration
We will be parsing the listing pages that IIS generates, where each file or folder will be translated into a DownloadEntry instance:
public class DownloadEntry
{
public bool IsDirectory;
public string Name;
public Uri SourceUrl;
public DateTime? LastModified;
//If IsDirectory is true, the corresponding directory on the file system where the
//files should be placed. Does not need to exist yet.
public string TargetPath;
public DownloadEntry()
{
}
public DownloadEntry(string name, Uri sourceUrl, string targetPath)
{
Name = name;
SourceUrl = sourceUrl;
TargetPath = targetPath;
}
}
Recursively exploring the directory contents can then be implemented by storing all encountered subdirectories so far onto a stack. Each iteration, we parse the contents of the listing page for that particular directory. All files in that directory are downloaded immediately, but all subdirectories are placed onto the stack for the next iteration.
This effectively downloads all files in a directory before exploring any of its subdirectories, but makes sure the entire directory hierarchy is downloaded before exploring any sibling directories (run the cmdlet with the -Verbose switch to see this in action).
public void Download(Uri sourceUrl, string targetPath)
{
Stack<DownloadEntry> entryStack = new Stack<DownloadEntry>();
entryStack.Push(new DownloadEntry("", sourceUrl, targetPath));
WriteObject(string.Format("Downloading files from "{0}"...", sourceUrl));
while (entryStack.Any())
{
DownloadEntry entry = entryStack.Pop();
_directoryCount++;
//Create the target directory if necessary.
if (Directory.Exists(entry.TargetPath) == false)
Directory.CreateDirectory(entry.TargetPath);
//Download the directory listing.
List<DownloadEntry> childEntries = DownloadListing(entry.SourceUrl, entry.TargetPath);
//Queue the child directory so we'll pick them up after we're finished with this directory.
if (Recurse == true)
{
//Queue the child directories in reverse order, so the one with the alphabetically
//smallest name ends up on top.
foreach (DownloadEntry childEntry in childEntries.Where(e => e.IsDirectory).Reverse())
entryStack.Push(childEntry);
}
//Process the files in this directory.
foreach (DownloadEntry childEntry in childEntries.Where(e => e.IsDirectory == false))
{
DownloadFile(childEntry);
}
}
WriteObject(string.Format("Finished downloading {0} files in {1} folders.", _fileCount, _directoryCount));
}
/// <summary>
/// Downloads the file represented by the given DownloadEntry and writes it to disk.
/// </summary>
private void DownloadFile(DownloadEntry childEntry)
{
//Download the file and set the LastModified date if known.
_client.DownloadFile(childEntry.SourceUrl, childEntry.TargetPath);
_fileCount++;
if (childEntry.LastModified != null)
File.SetLastWriteTimeUtc(childEntry.TargetPath, childEntry.LastModified.Value);
base.WriteVerbose(childEntry.TargetPath);
}
On the Powershell side of things, note that we don’t use Console.WriteLine() to display text from a cmdlet. Instead, we use WriteObject(), because it sends its output through the Powershell pipeline, allowing it to be redirected or passed to another cmdlet.
In the same way, we use WriteVerbose() to write detailed progress messages. Normally this output is not displayed, only when you run your cmdlet with the -Verbose switch these messages get displayed. This is an excellent way to provide a caller with a way to see what’s happening under the surface, while preventing your cmdlet to clutter the console window during normal execution.
Parsing a directory listing page
For a directory listing, IIS generates webpages of which the HTML looks like:
<html> <head><title>localhost - /ReleaseStaging/</title></head> <body> <H1>localhost - /ReleaseStaging/</H1> <hr> <pre> <A HREF="/">[To Parent Directory]</A><br> <br> 5/7/2015 3:34 PM <dir> <A HREF="/ReleaseStaging/Acme/">Acme</A><br> 5/7/2015 3:38 PM 168 <A HREF="/ReleaseStaging/web.config">web.config</A><br> </pre> <hr> </body> </html>
Note that we cannot parse this into an XDocument directly because of the unclosed <br> and <hr> elements, and the improperly escaped <title> and <h1> elements – we’ll have to strip these out first.
private static readonly Regex TitleElementRegex = new Regex(@"<title>.*</title>", RegexOptions.IgnoreCase);
private static readonly Regex H1ElementRegex = new Regex(@"<h1>.*</h1>", RegexOptions.IgnoreCase);
/// <summary>
/// Downloads and parses the IIS listing page for the given url.
/// </summary>
private List<DownloadEntry> DownloadListing(Uri listingUrl, string targetDir)
{
string html = _client.DownloadString(listingUrl);
//The returned HTML contains unclosed elements such as "<br>" and "<hr>", which are valid
//in HTML but not in xml. Replace them with closed versions so that it becomes valid xml.
html = html.Replace("<br>", "<br />")
.Replace("<hr>", "<hr />");
//Also, although contents of the <A> elements are escaped properly, the <title> and <H1>
//elements are not, which is a problem for folders with "&" in the name.
//Since we don't need these elements anyway, remove them.
html = TitleElementRegex.Replace(html, "");
html = H1ElementRegex.Replace(html, "");
//Get the <pre> element that contains all directory entries as "<A HREF=""></A>" lines.
XDocument xdoc = XDocument.Parse(html);
XElement preElt = xdoc.Root.Descendants("pre").Single();
//Locate all <A> elements with their href attributes and inner text, and create DownloadEntries from them.
//Note that there is usually one entry called "[To Parent Directory]", which we don't want
//to include as part of the result.
List<DownloadEntry> result = preElt
.Elements("A")
.Select(elt => ParseDownloadEntry(listingUrl, targetDir, elt, elt.PreviousNode as XText))
.Where(de => string.Equals(de.Name, "[To Parent Directory]", StringComparison.OrdinalIgnoreCase) == false)
.ToList();
return result;
}
/// <summary>
/// Matches a date/time string as returned by IIS, e.g. "7/22/2014 11:15 AM".
/// </summary>
private static readonly Regex LastModifiedRexeg = new Regex(@"(d+/d+/d{4}s+(d+:d+)s+[AP]M)", RegexOptions.IgnoreCase);
/// <summary>
/// Parses an "A" element into a DownloadEntry.
/// </summary>
private DownloadEntry ParseDownloadEntry(Uri baseUrl, string basePath, XElement aElement, XText precedingText)
{
string href = aElement.Attributes()
.Where(attr => string.Equals(attr.Name.LocalName, "href", StringComparison.OrdinalIgnoreCase))
.Select(attr => attr.Value)
.Single();
//href is relative; Create the DownloadEntry with an absolute version of the url.
DownloadEntry entry = new DownloadEntry();
entry.Name = aElement.Value;
entry.TargetPath = System.IO.Path.Combine(basePath, entry.Name);
entry.SourceUrl = new Uri(baseUrl, href);
entry.IsDirectory = entry.SourceUrl.AbsoluteUri.EndsWith("/");
//If there is text preceding the <A> element, it should contain the last modified date/time, try to parse it.
if (precedingText != null && string.IsNullOrWhiteSpace(precedingText.Value) == false)
{
Match match = LastModifiedRexeg.Match(precedingText.Value);
if (match.Success)
{
//IIS *should* report all times in UTC, but it seems to be off sometimes by one hour... (?)
entry.LastModified = DateTime.ParseExact(match.Value, "M/d/yyyy h:mm tt",
CultureInfo.InvariantCulture, DateTimeStyles.AllowWhiteSpaces | DateTimeStyles.AssumeUniversal);
}
}
return entry;
}
Running the cmdlet
Once you have compiled your cmdlet into a .dll, you can import it as a module into the Powershell console or ISE as follows:
Import-Module .MyCmdlets.dll
Now the cmdlet should be available in your current Powershell session. Try to invoke it (obviously, the source url should refer to an exising IIS virtual directory with directory listing enabled):
Copy-FromHttp -SourceUrl "http://localhost/Staging/Public/" -Recurse Downloading files from "http://localhost/Staging/Public/"... Finished downloading 13 files in 4 folders.
Or, if you want to see which files are being downloaded:
Copy-FromHttp -SourceUrl "http://localhost/Staging/Public/" -Recurse -Verbose Downloading files from "http://localhost/Staging/Public/"... VERBOSE: C:TempDownloadTestTest.txt VERBOSE: C:TempDownloadTest1.1BGInfo.def.xml VERBOSE: C:TempDownloadTest1.1Bginfo.exe
When you’re done developing and want your module to be available in every powershell session, simply copy it to one of Powershell’s module directories such as C:Windowssystem32WindowsPowerShellv1.0Modules, in a directory with the same name:
Debugging the cmdlet
If you want to debug your cmdlet from Visual Studio, you could just use the Debug / Attach to process menu option to attach to the powershell.exe process. Although this works, each time you start debugging you’ll have to navigate to your compiled .dll file and import it as a module, which becomes tedious rather quickly.
Luckily, there is an easier way, and that is to have Visual Studio start powershell and import your module for you. This can be configured in your project’s Debug settings by specifying C:WindowsSystem32WindowsPowerShellv1.0powershell.exe as the path to the external program to start for debugging, and -noexit "& Import-Module .MyCmdlets.dll" as the Command line arguments (sadly, the Powershell ISE doesn’t appear to allow specifying script on the commandline, so this only works for the Powershell console):
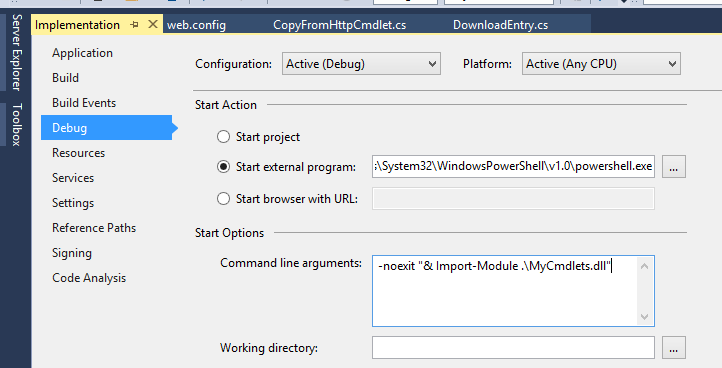
Now simply place some breakpoints and start debugging (F5) from Visual Studio.
Adding module help
Powershell is able to distill basic help information from your cmdlet by looking at its public properties and attributes used on them. You can see this by requesting the “full” help:
help Copy-FromHttp -full
As you can see the output is rather spartan, but it is possible to provide more complete help that includes a description and examples – this is done by including a MyCmdlets.dll-Help.xml file with your module. Microsoft provides some information about the various forms of module help.
To create your own module help file, I found that the most practical way is to just copy an existing help file (search C:WindowsSystem32WindowsPowerShellv1.0Modules for “*.dll-Help.xml” files) so that you get the structure right, and then modify the contents.
Summary
I think I’ve touched on the most important aspects of developing a cmdlet from C#, while at the same time providing a meaningful implementation capable of downloading multiple files a la robocopy, but over HTTP. I know I will be using this post as a quick reference in the future, and I hope you will too 😉