Why should I trust you: Het ''Waarom'' achter je Machine Learning voorspelling
Dat Machine Learning algoritmen toegevoegde waarde hebben voor de business wordt voor de business gelukkig steeds duidelijker, maar voor de beslissers in de business is het eng om advies van een Machine Learning algoritme blindelings op te volgen. Vooral bij de ingewikkelde ML algoritmen is dit een serieus probleem; de reden dat het algoritme tot een bepaalde beslissing is gekomen is totaal ondoorzichtig. Hoe weten we of het onderliggende verband dat het algoritme gevonden heeft niet gebaseerd is op toeval? Is er een manier om een ingewikkeld ML model en de bijbehorende voorspelling inzichtelijk maken voor de business?
Deze vraag kwam enige tijd terug bij mij terecht en goed nieuws: dat kan met LIME! LIME schept vertrouwen in Machine Learning modellen door de redenering erachter te laten zien en het stelt individuen die geen ML-expert zijn in staat om nutteloze en onzinnige features te spotten en hiermee het model te verbeteren (feature engineering). Ik heb me verdiept in het verklaren van Machine Learning modellen in het algemeen en LIME in het specifiek en hier ook sessies over gevolgd op PyData Amsterdam. LIME is geen magische oplossing voor alles, maar ik leg in de komende paragrafen uit hoe LIME werkt en wat de limitaties hiervan zijn.
ML voor de business
Laatst kreeg ik de vraag of ik een model kon maken met echte business impact. Een model dat kan voorspellen of klanten op het punt staan om weg te gaan (zogenaamde customer churn), zodat je contact kan opnemen met deze klant en wellicht de voorwaarden in het contract gunstiger maken zodat deze klant niet zal vertrekken. Je kan je voorstellen dat dit zeer gunstig is, maar dat dit ook heel nauwkeurig moet gebeuren; als je niet correct gedetecteerd had dat een klant wilde vertrekken en deze klant gaat inderdaad weg, dan kost dat geld, maar het bieden van extra korting aan een klant die helemaal niet van plan was om weg te gaan kost ook geld. Daarom is het voor de business cruciaal om te weten aan welke klanten ze extra tijd en aandacht moeten besteden, maar zijn ze sceptisch als er bijna ‘magisch’ een voorspelling uit het model komt rollen zonder verdere verklaring of toelichting. En dat is volledig terecht; je wilt je beleid altijd kunnen verantwoorden en niet baseren op een beslissing onbegrijpelijk voor mensen.
Machine Learning modellen kunnen erg ingewikkeld worden: bij een lineair model is het verband tussen de voorspelling en de onderliggende features nog relatief makkelijk te begrijpen, bij een Decision Tree wordt het al iets ingewikkelder, en als je 100 beslisbomen samenvoegt tot een Random Forest, kun je het dan nog steeds verklaren? En als het nog ingewikkelder wordt en je Deep Learning gaat gebruiken, weet je dan nog waarom je model tot een bepaalde beslissing is gekomen? De case van customer churn is een ideale gelegenheid om me te verdiepen in het gebruik van LIME.
Wat is LIME?
LIME staat voor Local Interpretable Model-agnostic Explanations en is in 2016 in het leven geroepen door Ribeiro, Singh & Guestrin. In hun artikel beschrijven ze het belang van vertrouwen in een ML voorspelling (een model dat niet vertrouwd wordt, wordt ook niet gebruikt) en doen ze een poging vertrouwen te verhogen door een redelijke verklaring te geven voor de voorspellingen van anderszins black-box modellen. De resultaten zijn veelbelovend en er wordt door een van de auteurs een Python package ontwikkeld op basis van deze paper.
Hoe LIME precies werkt wordt al een beetje verraden door de eerste twee letters, namelijk Local en Interpretable. Dat wil zeggen, het doel is interpreteerbaar en lokaal getrouwe resultaten te leveren. Deze zijn onafhankelijk van welk black-box model je erin gooit (Model-agnostic) en dit alles in de vorm van een Explainer.
Gaaf, dus LIME verklaart waarom je model een bepaalde keuze heeft gemaakt? Nou nee, niet precies. LIME doet een poging om je black-box model te verklaren, maar doet dat door een lineaire benadering te maken van de resultaten per datapunt (dus zeer lokaal) en visualiseert dan de mate waarin features van invloed waren op de classificatie van dat datapunt. Dit doet het door per datapunt honderden of duizenden permutaties te maken; kunstmatige datapunten die allemaal iets anders zijn in de features die ze hebben, en hierop een lineair model te trainen.
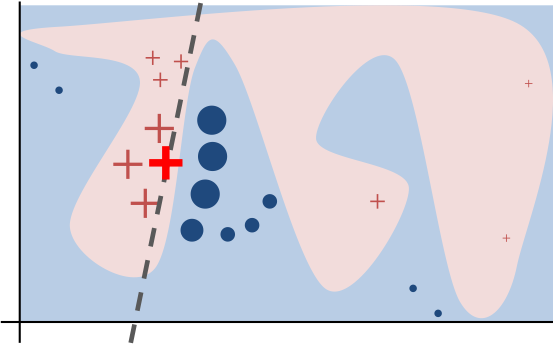
Het idee is dat, ook al is een onderliggend verband in de data erg complex, als je maar ver genoeg inzoomt op de individuele datapunten kun je met een lineair model iets maken dat zeer lokaal wel correct is. Zelf illustreren ze dit met de volgende afbeelding:

Voorbeeld van lokale verklaring op kunstmatige data (Ribeiro et al., 2016)
In dit plaatje is het onderliggende verband erg complex, maar is de situatie van het dikgedrukte kruis desondanks wel te verklaren met een simpel lineair model. Dit model generaliseert totaal niet naar de rest van de datapunten, maar LIME geeft per datapunt een verklaring van de invloed van verschillende features en voor dit specifieke datapunt (het dikgedrukte kruis) is de lineaire classifier perfect in staat om dit te doen.
LIME toegepast customer churn
Terug naar de case van customer churn: het is niet voldoende om alleen een model te hebben dat churn goed voorspeld. Als het model namelijk accuraat is met zijn voorspellingen zal het business beleid hierop aangepast moeten worden en zal marketing de klanten, die anders zouden weglopen, een mooi aanbod moeten doen. Maar waarom loopt die klant eigenlijk weg? En wat is er nodig om deze klant te laten blijven? Als we wisselen van een jaarcontract naar een maandcontract, wat doet dat met de kans dat deze klant vertrekt? Dit zijn allemaal vragen die ontzettend relevant zijn voor de business, maar bij een machine learning model niet triviaal om te beantwoorden.
De dataset die ik voor mijn demo gebruikt heb is een sample dataset van IBM over customer churn in de telecom sector. Nu is de telecom sector niet de enige sector die baat heeft bij een churn model, maar deze dataset werkt prima om de business value van LIME te illustreren. De dataset bevat 7043 rijen en 19 kolommen met features en de target kolom churn: deze kolom geeft aan of de klant in de afgelopen maand is weg gegaan. De data is niet gebalanceerd en de churners zijn in de minderheid (26,5%). Er zijn kolommen als Phone Service, Internet Service, Tech support etc. die gevuld zijn met Yes, No en andere categorische variabelen. Op dit punt nog erg overzichtelijk en makkelijk te begrijpen. Echter, een ML algoritme heeft liever geen tekst als input, maar getallen.
Na het bewerken van de data zijn er wat kolommen weggegooid en zijn er nieuwe kolommen bij gekomen allemaal gevuld met nullen en enen. Het model dat het beste werkte op deze data is een Random Forest. Dit is een heel bos van beslisbomen die samen tot een label komen. Het Random Forest algoritme staat erom bekend dat het erg goed werkt met data die categorisch is en waarbij de verbanden niet-lineair zijn, maar het is ook berucht om zijn ondoorzichtigheid en hoe moeilijk is om de uitkomsten te interpreteren. Normaalgesproken wordt een model beoordeeld op zijn metriken: een hogere accuracy zal wel een beter model opleveren, maar dit is niet altijd het geval. Soms generaliseert een model dat een hogere accuracy haalt slechter naar de ‘echte wereld’. Dit kan zijn omdat het model verbanden heeft geleerd die niet de bedoeling waren (je hebt bijvoorbeeld klantnummer meegenomen als kolom), of je data is gewoon rommelig en er zit veel ruis in. Het probleem is: dit is niet te zien aan alleen de accuracy.
Een Random Forest is een combinatie van beslisbomen en die zijn makkelijk te interpreteren; is een RF dan ook te interpreteren? Ja en nee; het uiteindelijke resultaat is een gemiddelde van honderden random geïnitialiseerde beslisbomen en daarin erg ondoorzichtig. Wel kan de RF, net als de Decision Tree, een output geven van de zogenaamde feature importance van alle features meegenomen in het model. De output hiervan is een lijst met allemaal getallen met heel veel decimalen. Deze getallen representeren de mate waarin een een feature een rol heeft gespeeld in de classificatie van alle datapunten. Dit geeft alleen een aantal problemen: wat betekenen deze getallen? Dat een feature belangrijk is in de classificatie zegt helemaal niks over op welke manier deze feature dan belangrijk is. En het tweede probleem in dit geval is het feit dat de output van de feature importances niet overeenkomt met de kolommen die het model in gaan. Om de data klaar te maken voor ML algoritmen wordt de data namelijk geëncodeerd naar extra kolommen. En het Random Forest model vertelt dat een aantal van die geëncodeerde kolommen belangrijk zijn, maar het kan niet vertellen welke kolommen dat oorspronkelijk waren. Ook kan het model geen verklaring geven over individuele datapunten, terwijl dat voor marketing juist de meest relevante vraag is: ‘Waarom gaat deze specifieke klant bij ons weg, en welke aanbieding kunnen we doen zodat deze klant blijft?’

Welke features zijn nou belangrijk en op welke manier beïnvloeden ze de classificatie?
De feature importances zoals in het figuur hierboven zijn zelfs voor een expert lastig te interpreteren, laat staan voor iemand die geen kennis heeft van de onderliggende technologie. Laten we dit vergelijken met de output van LIME:


LIME output van de voorspelling van een enkel datapunt
Deze output is al een stuk beter te begrijpen. De features zijn terug gebracht naar de originele namen van de kolommen en de invloed per feature is weergegeven met kleurtjes, maar hoe interpreteer je dit? De oplettende lezer heeft misschien wel gezien dat de getallen bij de features niet optellen tot de prediction probabilities en dat klopt. Volgens de documentatie van LIME moet je de getallen bij de features interpreteren als zijnde: ‘als ik deze feature niet mee zou nemen, zou de prediction probability voor deze klasse (kleur) met zo veel afnemen’. Dit is iets waar marketing iets mee kan. In dit specifieke geval heeft contracttype een grote invloed op de voorspelde churn; wat als we de data van deze klant nog een keer door het ML algoritme gooien, maar dan met een ander contracttype, blijft deze klant dan wel? Op deze manier kan marketing het model zelf interpreteren zonder de uitleg van een Machine Learning expert en hebben ze een idee hoe ze zelf klantgedrag zouden kunnen beïnvloeden. Sterker nog, ze kunnen de ML expert helpen met zogenaamde feature engineering, door als er features in de output verschijnen die voor ons mensen met veel achtergrondkennis totaal niet logisch lijkt, de ML expert erop te attenderen dat er ongewenste features tussen staan en hiermee het model verbeteren. En omdat het model voor de betrokkenen niet meer als een black-box wordt gezien, neemt het vertrouwen in het model toe.
Wat zijn de trends op PyData?
Machine Learning is al een paar jaar aan het groeien in populariteit en het is ‘hip en happening’. De trend was een tijdje terug om zo veel mogelijk features in een zo ingewikkeld mogelijk model te gooien, het liefst een Neural Network, om een zo hoog mogelijke accuracy te halen op een testdataset en om hier bijvoorbeeld Kaggle competities mee te winnen. Gelukkig, nu het vakgebied van Data Science volwassener wordt, lijkt de trend te gaan richting het kunnen verklaren van je modellen. Als je de voorspelling van je ML model niet uit kan leggen aan een niet-technische collega, dan heb je geen goed model. En deze trend is ook terug te zien op PyData.
Op de zaterdag was er een erg leuke sessie van Ian Ozsvald waarin hij verschillende manieren laat zien om data en features te visualiseren en hierbij onderliggende verbanden te tonen. Door je data distributie te visualiseren en in detail naar features te kijken komen fouten in je data goed naar voren en zie je of de aannames die je doet over de data stand houden. Ian demonstreert dit heel mooi aan de hand van een aantal Python packages en visualisatie methodes en laat zelfs een alternatief zien voor LIME, namelijk SHAPly. Dit alles demonstreert hij op een bekend en pakkend voorbeeld: de Titanic dataset. Zijn manier van vertellen is erg leuk en het verhaal is goed te begrijpen, ook voor niet-experts.
Gelukkig was Ian Ozsvald niet de enige die aandacht schenkt aan het verklaren van modellen. Ook Tobias Sterbak geeft een sessie over het verklaren van modellen. Hij laat zien hoe, toegepast op tekstclassificatie, een hoge accuracy niet hoeft te betekenen dat je een goed model gebouwd hebt. Door LIME te gebruiken in de context van tekstclassificatie zie je welke ‘verkeerde’ features je model gebruikt. Zo kan bijvoorbeeld, bij het classificeren van topic, de naam een auteur sterk correleren met een onderwerp (omdat deze persoon vaak over dezelfde onderwerpen praat). Dit geeft een hoge accuracy op je testdata, maar generaliseert totaal niet. Je model is snel geneigd om verbanden te leren in de dataset, in plaats van leren over het onderliggende probleem of vraagstuk. Met libraries zoals LIME maak je inzichtelijk waar het model zijn keuze op baseert. Tobias laat ook zien dat LIME in niet alle gevallen een nuttige output geeft, maar dat er wel weer manieren zijn om dat inzichtelijk te maken. Ook laat hij eli5 zien; een Python library die visualisaties bouwt bovenop de LIME explanations.
Een andere sessie waar ik erg van genoten heb gaat niet zo zeer over het verklaren van ML modellen, maar staat wel nauw in verband met de volwassenheid van het vakgebied van Data Science. We doen in het analyseren van data en het schrijven van code allerlei aannames over onze data en in de software ontwikkeling is het al standaard om deze aannames expliciet te maken in de vorm van unit tests, maar in de Data Science is dit nog niet standaard. Jane Stewart Adams verteld in haar sessie over aannames die ze doet over haar data en hoe je deze expliciet kan maken en de Python library die ze ontwikkeld hebben om dit allemaal mogelijk te maken: Marbles. In tegenstelling tot software engineering, waar een aanpassing die jij doet lijdt tot een falende unittest, liggen veranderingen in je binnenkomende data vaak buiten jouw macht. Daarom is het belangrijk dat je goede tests schrijft met een beschrijvende omschrijving die uitlegt waarom een bepaalde aanname getest wordt en die het expliciet maakt als een aanname niet meer klopt. Zodat je model kan blijven draaien en dat, als je jaren later een falende unittest hebt, je meteen duidelijk hebt wat er aan de hand is. Dit kan allemaal met Marbles.
Conclusie
Machine Learning kan van enorme toegevoegde waarde zijn voor de business door voorspellingen te geven over bijvoorbeeld customer churn, maar dit kan alleen als de beslissers die moeten handelen op de voorspelling uit het model deze ook vertrouwen. Om dat vertrouwen te creëren moet een model per datapunt kunnen verklaren waarom het tot een specifieke beslissing is gekomen. Ik heb laten zien dat, in het geval van customer churn, LIME een output geeft die voor niet-experts goed te begrijpen is. Op PyData heb ik een alternatief gezien voor LIME, namelijk SHAPly. Ik ga me zeker verder verdiepen in beide Python packages en onafhankelijk van welke beter is zijn ze beide een waardevolle stap richting duidelijke doorzichtige modellen voor de business.
Het vakgebied van Data Science is aan het verschuiven van een stel experts dat elkaar probeert te verslaan op accuracy in een onbegrijpelijk model voor een Kaggle wedstrijd, naar een behoefte aan verklaringen. De realisatie dat metrieken zoals accuracy een vertekend beeld kunnen geven van je model begint steeds meer door te dringen en er wordt veel aandacht besteed aan het verklaren van resultaten. Ook reproduceerbaarheid en integriteit van de data krijgen steeds meer aandacht. Duidelijkheid en verklaarbaarheid wordt de nieuwe standaard: iemand zonder kennis van de gebruikte techniek moet begrijpen waarom een keuze gemaakt wordt en moet (met eventuele domeinkennis) kunnen inschatten of deze beslissing ook logisch is.
Naar mijn mening is dit een zeer goede ontwikkeling die ons gaat helpen om de business te laten zien dat Machine Learning in zijn huidige staat bijzonder weinig te maken heeft met Sci-fi en zelfbewuste machines, maar dat het eerder een tool is om verbanden te ontdekken en hiermee mensen te helpen in het nemen van beslissingen of het automatiseren van taken die tijdsintensief kunnen zijn.
Of de robot opstand apocalyps er ooit gaat komen weten we niet, maar met libraries zoals SHAPly en LIME kunnen we ons druk maken om vragen die er echt toe doen in de business: hoe minimaliseren we churn en houden we klanten tevreden?